Background: Business Architecture
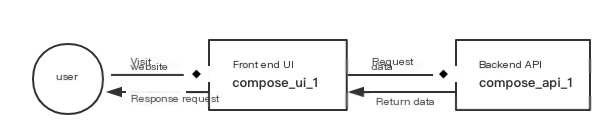
Business Architecture:
 >
>
Deployment Details: Both containers are deployed on the same machine, orchestrated by docker-compose, and linked via link.
Business Architecture Issue Description
During a code update, the frontend could open, but all interface requests returned 502 (Bad Gateway)
 >
>
Issue Troubleshooting
Checking the logs of the frontend container compose_ui_1, there was a flood of 502 (Bad Gateway)

If there’s no issue with the UI, the first reaction is that compose_api_1 has failed, so I directly went to the container to check the logs.
The container logs appear normal, no crashes, and the logs seem as if they’ve never received a request, but I’m sure my frontend accessed it, which feels odd. I tried accessing the interfaces separately to see if there’s any change:

Accessing the interface separately still results in a brutal 502 (Bad Gateway), which seems unreliable. Could there be a port or host access error? I used Wireshark on the host to confirm the request’s host and port:

With this, it’s certain the host and port accessed by the frontend compose_ui_1 are correct, and the precise result is a 502 (Bad Gateway). This means the issue must be investigated from compose_api_1.
A similar issue was encountered before, because compose_api_1 is deployed through uwsgi with python flask. There were some usage issues in the past, but after modifying uwsgi configurations, it quieted down for a while. Now it’s back.
First, let’s determine if compose_api_1 truly failed… even though hope is low…
Accessing the backend API interface directly.
Uh…awkward…seems like I wrongfully accused someone. This shouldn’t be right, let’s sniff with packet capture again to confirm:

It really seems to be…let’s take another look at the container logs:

Uh…okay…I’ve made a mistake, compose_api_1 hasn’t failed.
So the problem arises…Backend interfaces work fine, but there’s an error accessing from the frontend, what’s going on?
I have a hunch it’s an issue due to the characteristics of the container. Hopefully not…
Let’s go into the compose_ui_1 container to capture packets and analyze if there’s any problem in the entire request chain:

There seems to be some trickery, Flags[R.] represents the TCP connection being reset, but why is it reset for no reason?
Seeing what’s returned from 172.17.0.5.8080, let’s telnet and ask first:

What??? This is puzzling, first, where did this 172.17.0.5.8080 come from? Secondly, why is the port inaccessible?
Suddenly remembered an important issue:
JavaScript codeCopy
How do containers know where to send their requests to?As discussed earlier, these two containers are linked via link, like this:
Searched Google about how the link mechanism works:
JavaScript codeCopy
The link mechanism provides such information through environment variables, in addition to which database passwords and such information will also be provided through environment variables. Docker imports all environment variables defined in the source container into the received container, where you can use environment variables to get connection information.After using the link mechanism, you can communicate with the target container through a specified name, which is actually achieved by adding a name and IP resolution relationship to /etc/hosts.So, in compose_ui_1, it translates the specific IP from the specified name and allows communication via /etc/hosts.What is the container’s name?

compose_ui_1’s /etc/hosts
JavaScript codeCopy
root@e23430ed1ed7:/# cat /etc/hosts127.0.0.1 localhost::1 localhost ip6-localhost ip6-loopbackfe00::0 ip6-localnetff00::0 ip6-mcastprefixff02::1 ip6-allnodesff02::2 ip6-allrouters172.17.0.4 detectapi fc1537d83fdf compose_api_1172.17.0.3 authapi ff83f8e3adf2 compose_authapi_1172.17.0.3 authapi_1 ff83f8e3adf2 compose_authapi_1172.17.0.3 compose_authapi_1 ff83f8e3adf2172.17.0.4 api_1 fc1537d83fdf compose_api_1172.17.0.4 compose_api_1 fc1537d83fdf172.17.0.6 e23430ed1ed7If the information is correct, 172.17.0.4:8080 should be the correct address mapping for compose_api_1, right? Let’s test it first.

Even though it returned auth product is None, this is actually a valid request.
Next, check the logs of the compose_api_1 container:

So, no further running around is needed. The reason the frontend access directly gives a 502 is that the UI container is sending requests to the wrong address
But why is it like this? Did it go berserk for no reason?
Earlier, based on the host’s record experiment, sending interface requests according to its mapped address faced no issue:
Checking the nginx logs of compose_ui_1

Awkward… The nginx logs directly connect to standard output and standard error… To simplify, I used docker logs to check.

Looks like nginx‘s forwarding is wrong. Why does it forward to 172.17.0.5? Let’s look at nginx‘s forwarding configuration:
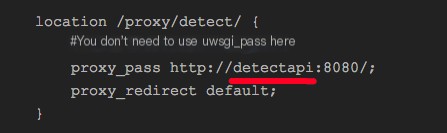
This detectapi can find the correct address 172.17.0.4 in the hosts table above, right? I can’t figure out why it would forward to 172.17.0.5
Could it be a domain name resolution error in the system?
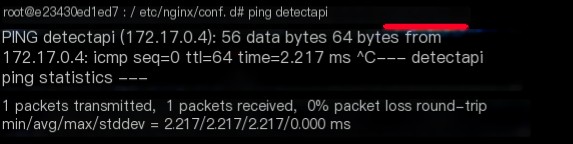
This is truly bizarre.
A man’s intuition tells me there’s something suspicious with nginx!
Restarting the container’s nginx, yet the container also gets restarted…

Reaccessing the page, and it works now…
Rechecking the container’s nginx logs confirms successful forwarding

With this, it can be pinpointed; the issue stemmed from nginx?
Fault Localization
But why would nginx have such an error? It shouldn’t be. It feels like it’s an internal nginx domain name resolution cache issue.
Upon checking references, yep, there really is one. https://www.zhihu.com/questio…

This is quite embarrassing. Skeptical about this issue, I consulted a senior expert, and his reply was:
JavaScript codeCopy
If proxy_pass is followed by a domain name, it is initialized when nginx starts and will reuse this value; refer to: ngx_http_upstream_init_round_robin function.If proxy_pass is followed by upstream, then it takes the parsing and caching logic.Improvement Measures
- Instead of
proxy_passdirectly to real domain names, forward toupstreamconfiguration; - Also refer to the treatment plan in the earlier Zhihu link: https://www.zhihu.com/questio…;
Additional Problems
- Why did the specified
compose_api_1incompose_ui_1produce an error? - If
proxy_passis followed by a real domain name, is it directly reused, or is there a time cache?
I originally wanted to use gdb to debug this issue, but after spending a day, nothing came of it. However, there was a small takeaway, which is how to configure nginx to support gdb:
1. Edit the compile configuration file: auto/cc/conf
JavaScript codeCopy
ngx_compile_opt="-c" change to ngx_compile_opt="-c -g"2. During ./configure, add the compile parameter: --with-cc-opt='-O0', to avoid compiler optimization;Example: ./configure --prefix=/usr/local/nginx --with-cc-opt='-O0' ....Without this, the compiler optimizes the code, making it impossible to print some loop variable values during debugging, resulting in errors like below:
JavaScript codeCopy
value optimized outHere you can see the debugging effect:Entry point for processing in the nginx worker process: ngx_http_static_handler