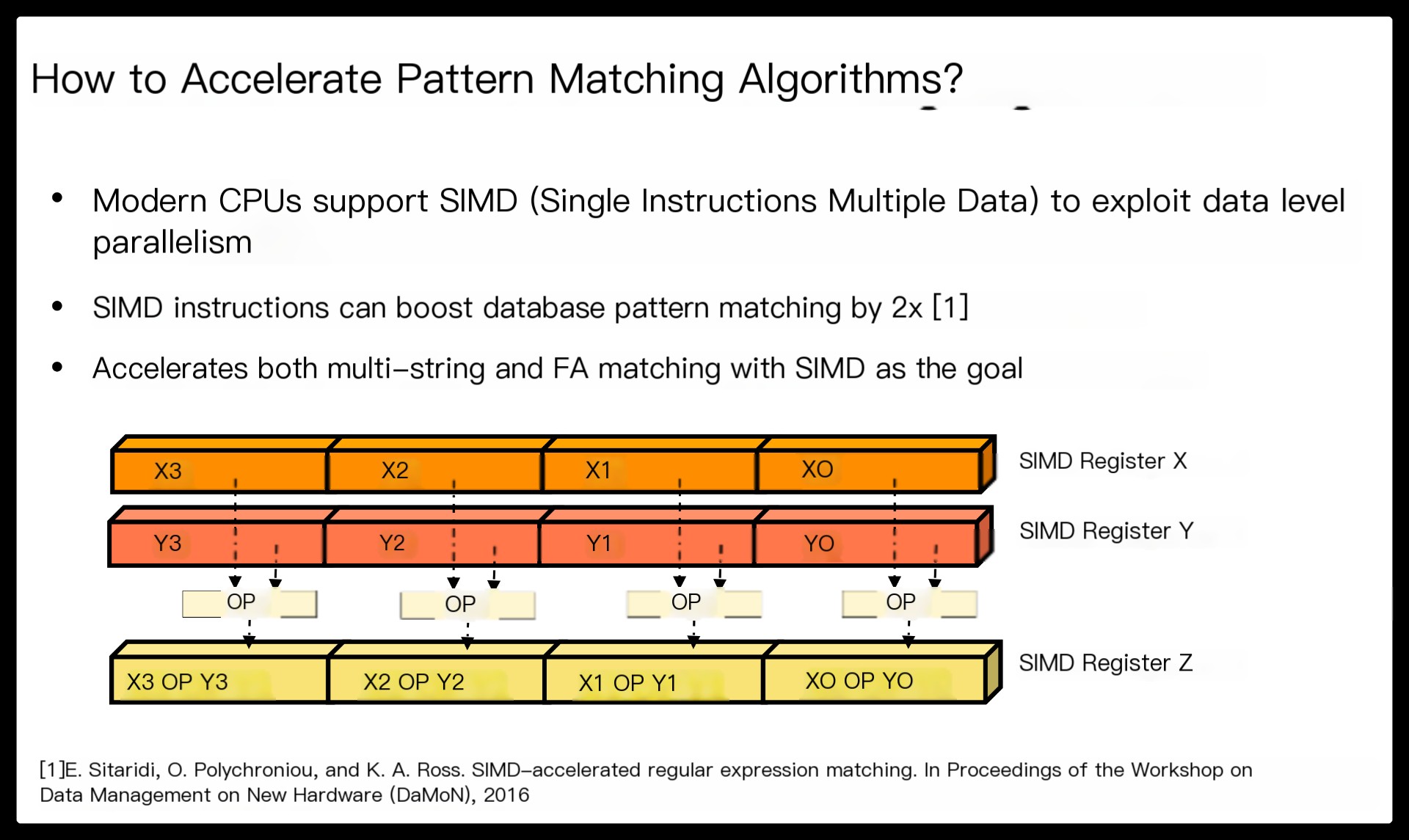
A SIMD instruction executes the same operation on multiple data in parallel.
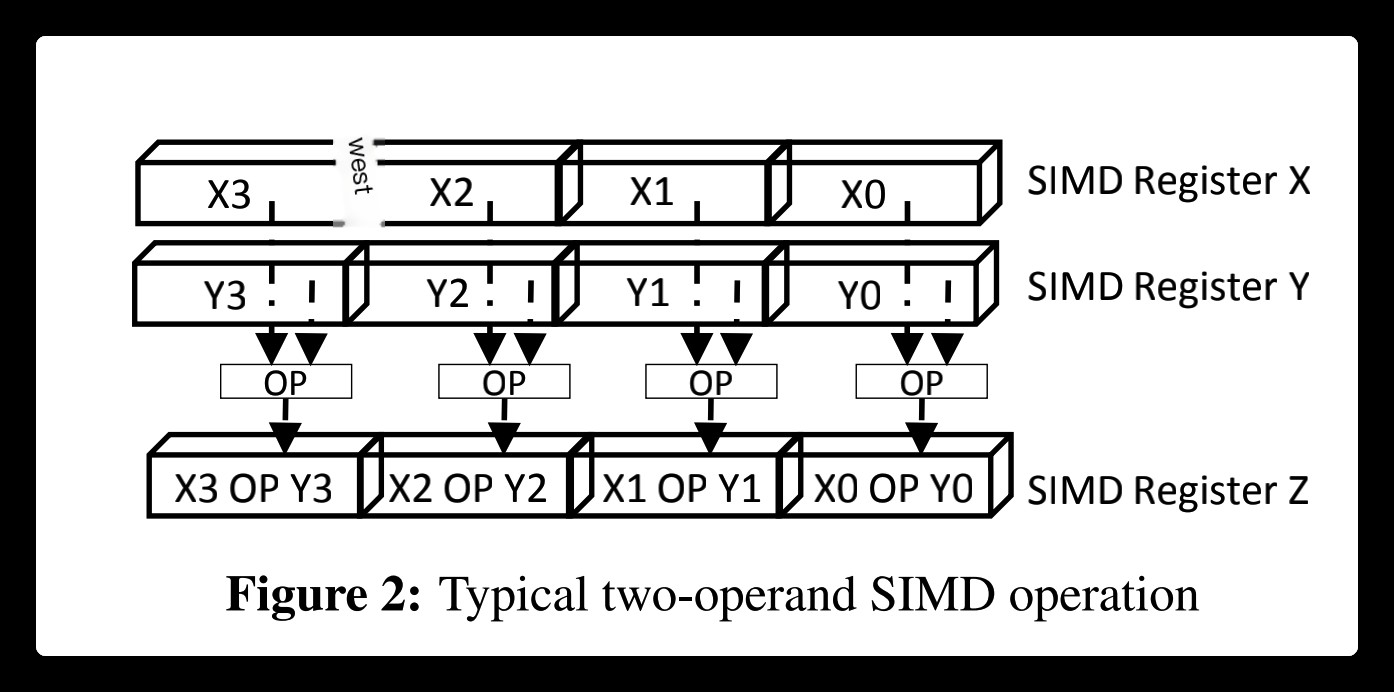
A SIMD Operation
A SIMD operation is performed on multiple lanes of two SIMD registers independently, and the results are stored in the third register. Modern CPUs support a number of SIMD instructions that can work on specialized vector registers (SSE, AVX, etc.). The latest AVX512 instructions support up to 512-bit operations simultaneously.
Hyperscan: A Fast Multi-pattern Regex Matcher for Modern CPUs
Regular expression matching serves as a key functionality of modern network security applications. Unfortunately, it often becomes the performance bottleneck as it involves a compute-intensive scan of every byte of packet payload. With trends towards increasing network bandwidth and a large ruleset of complex patterns, the performance requirement becomes ever more demanding. In this paper, we present Hyperscan, a high-performance regular expression matcher for commodity server machines.
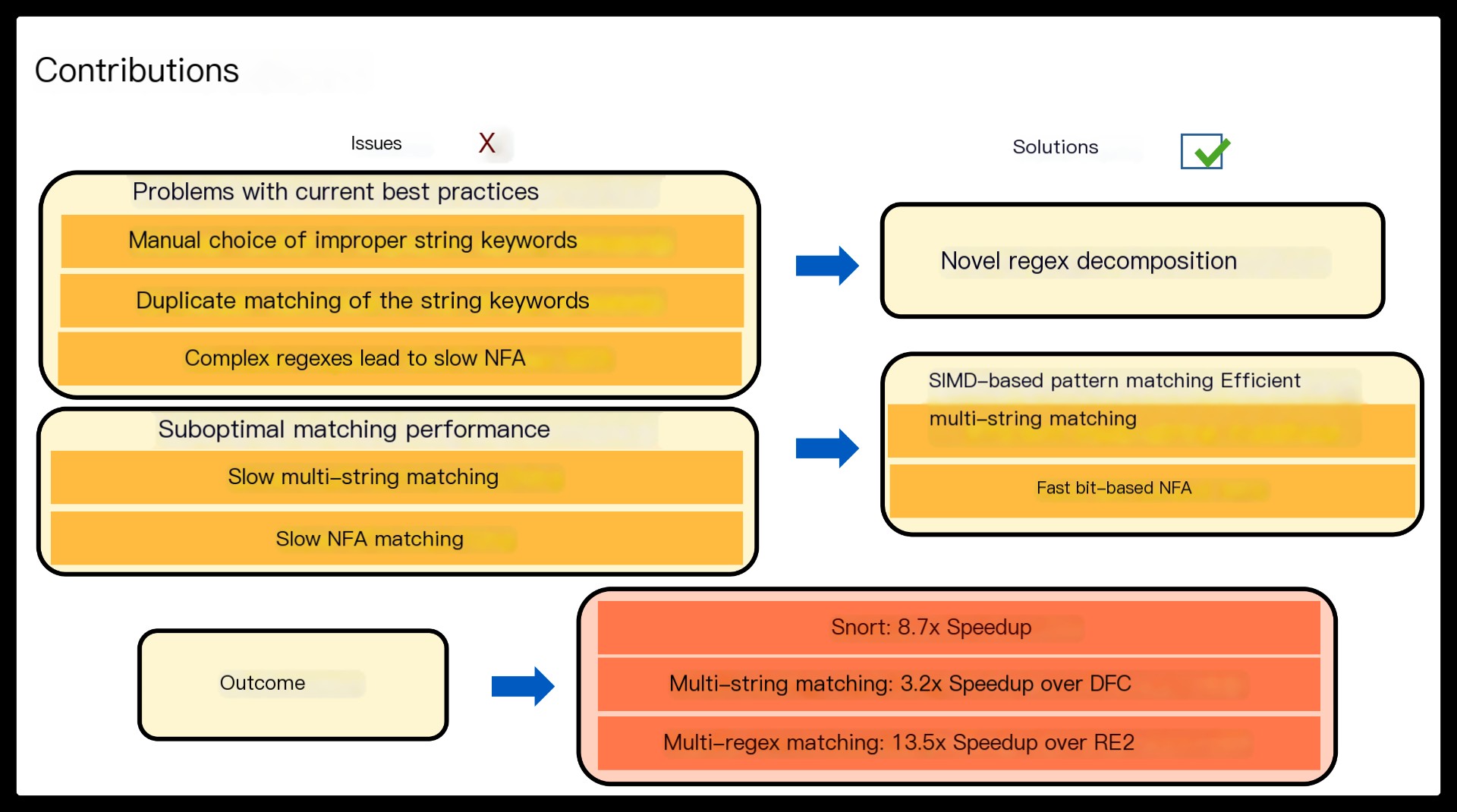
Hyperscan employs two core techniques for efficient pattern matching.
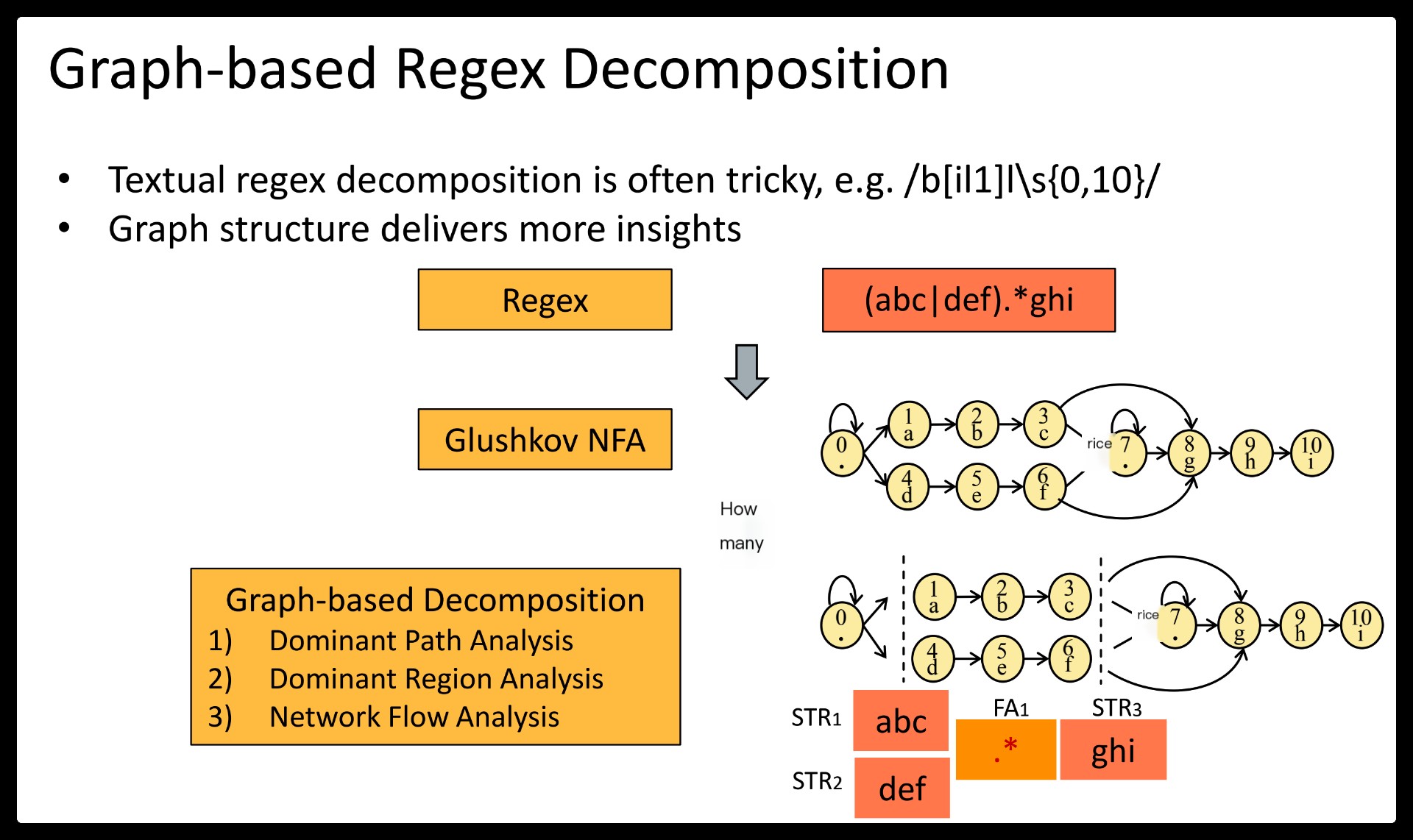
– First, it exploits graph decomposition that translates regular expression matching into a series of string and finite automata matching. Unlike existing solutions, string matching becomes a part of regular expression matching, eliminating duplicate operations. Decomposed regular expression components also increase the chance of fast DFA matching as they tend to be smaller than the original pattern.
– Second, Hyperscan accelerates both string and finite automata matching using SIMD operations, which brings substantial throughput improvement.
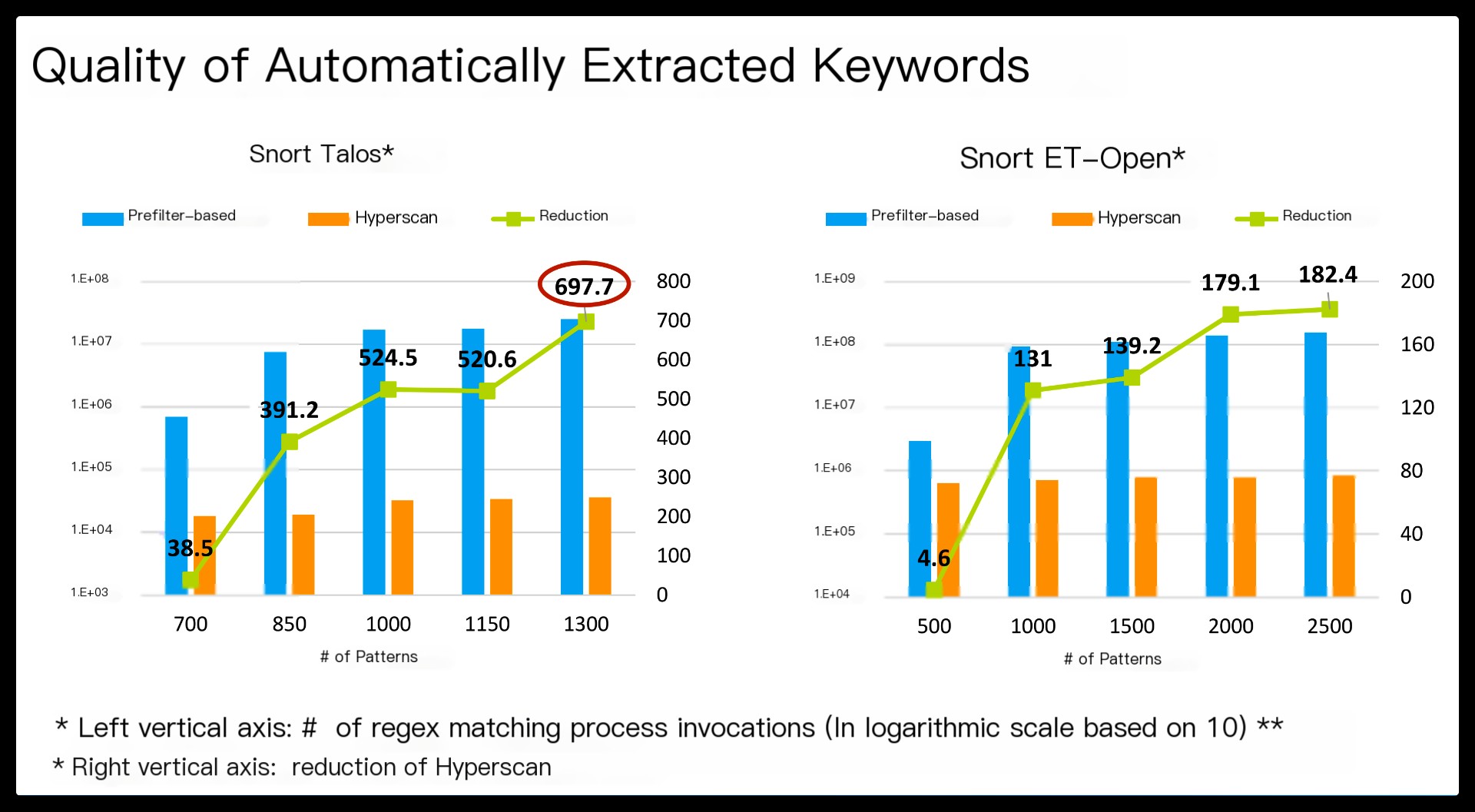
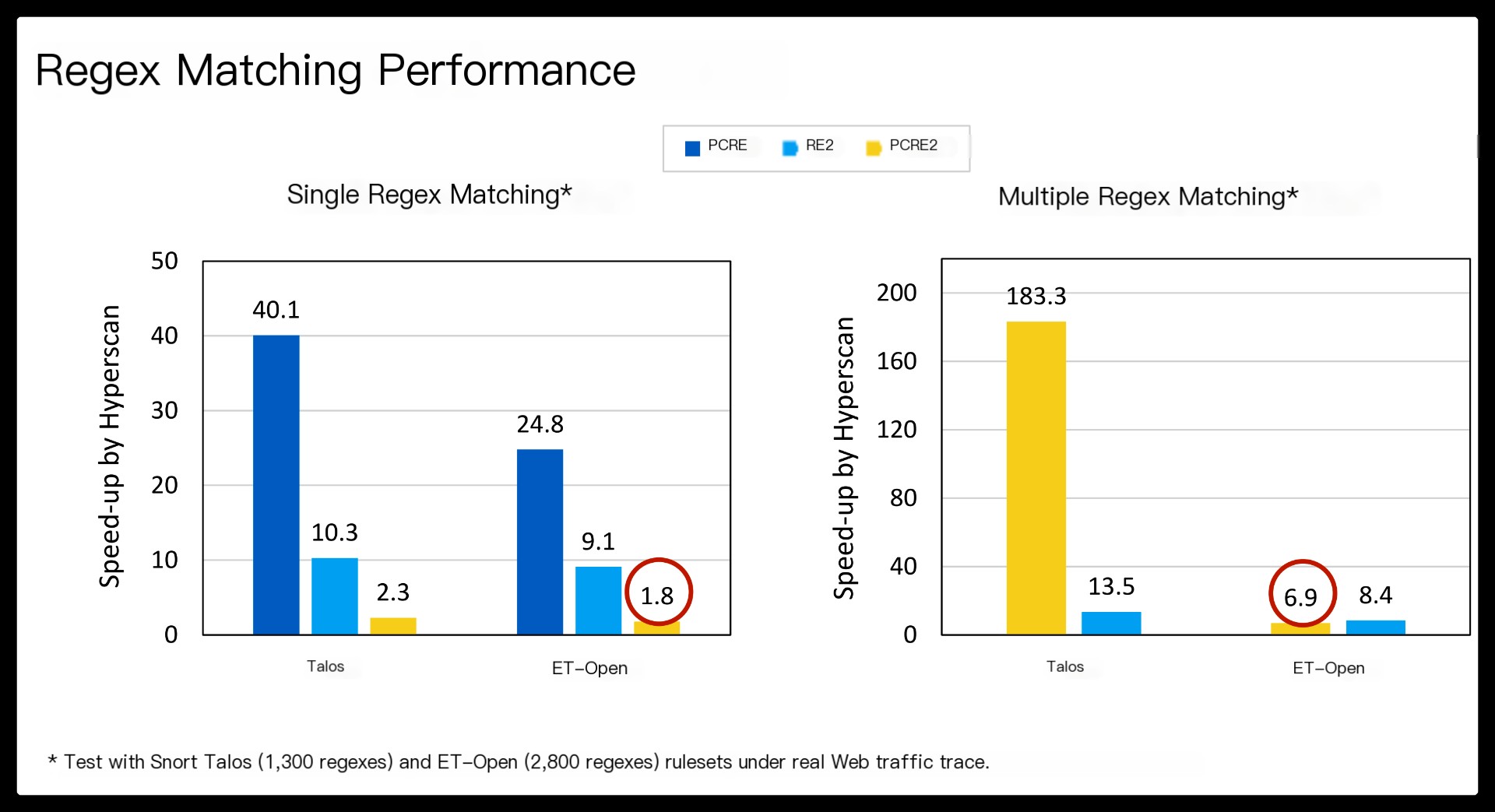
Our evaluation shows that Hyperscan improves the performance of Snort by a factor of 8.7 for a real traffic trace.
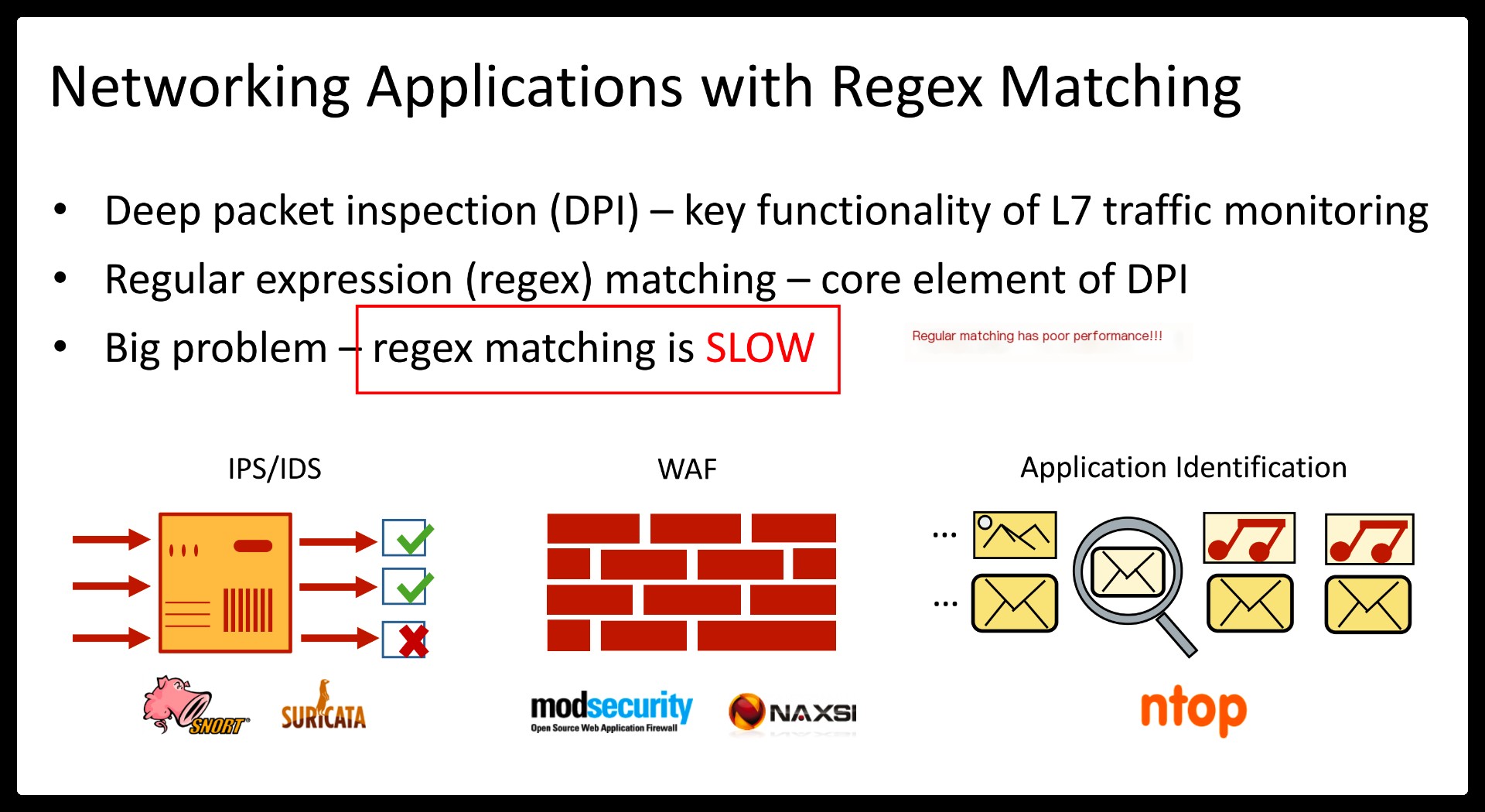
Deep packet inspection (DPI) provides the fundamental functionality for many middlebox applications that deal with L7 protocols, such as intrusion detection systems (IDS).
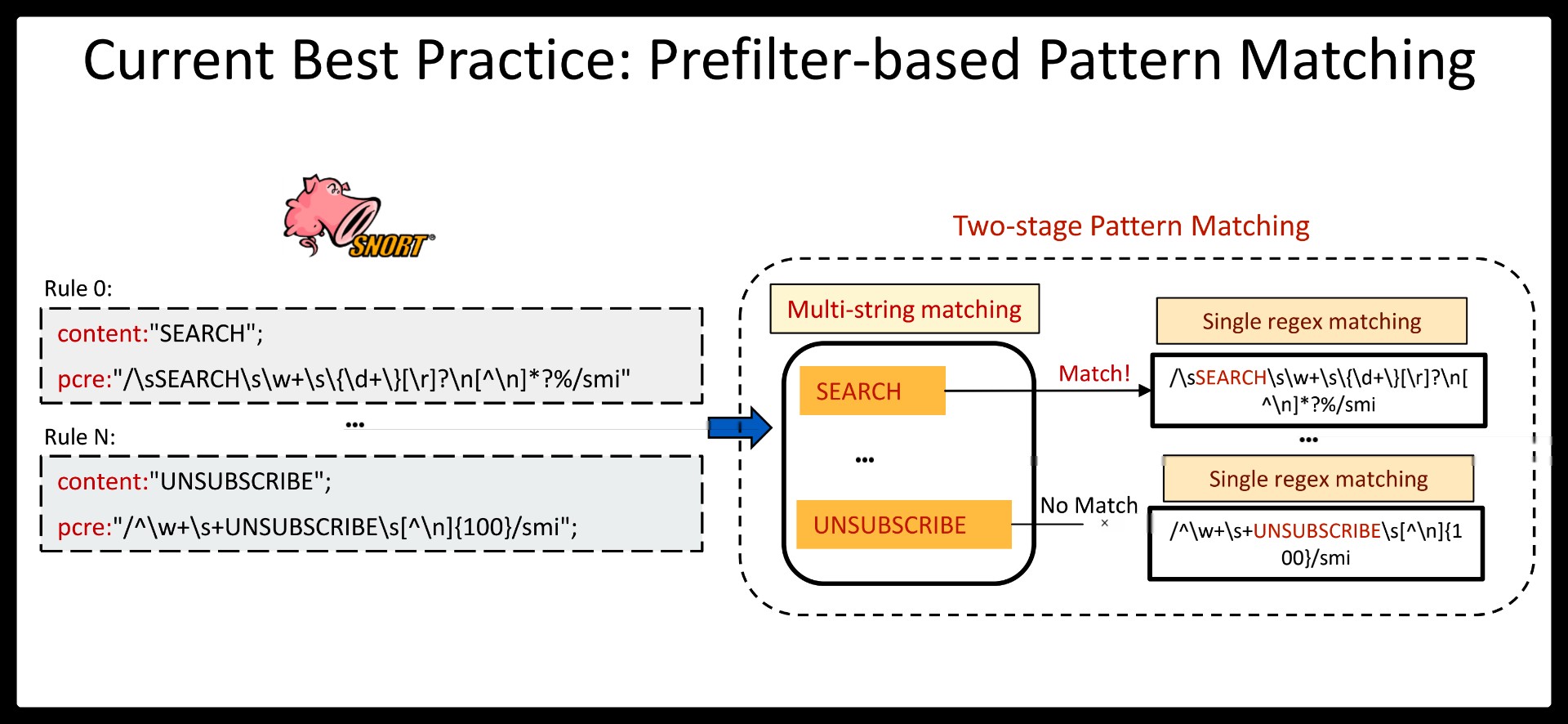
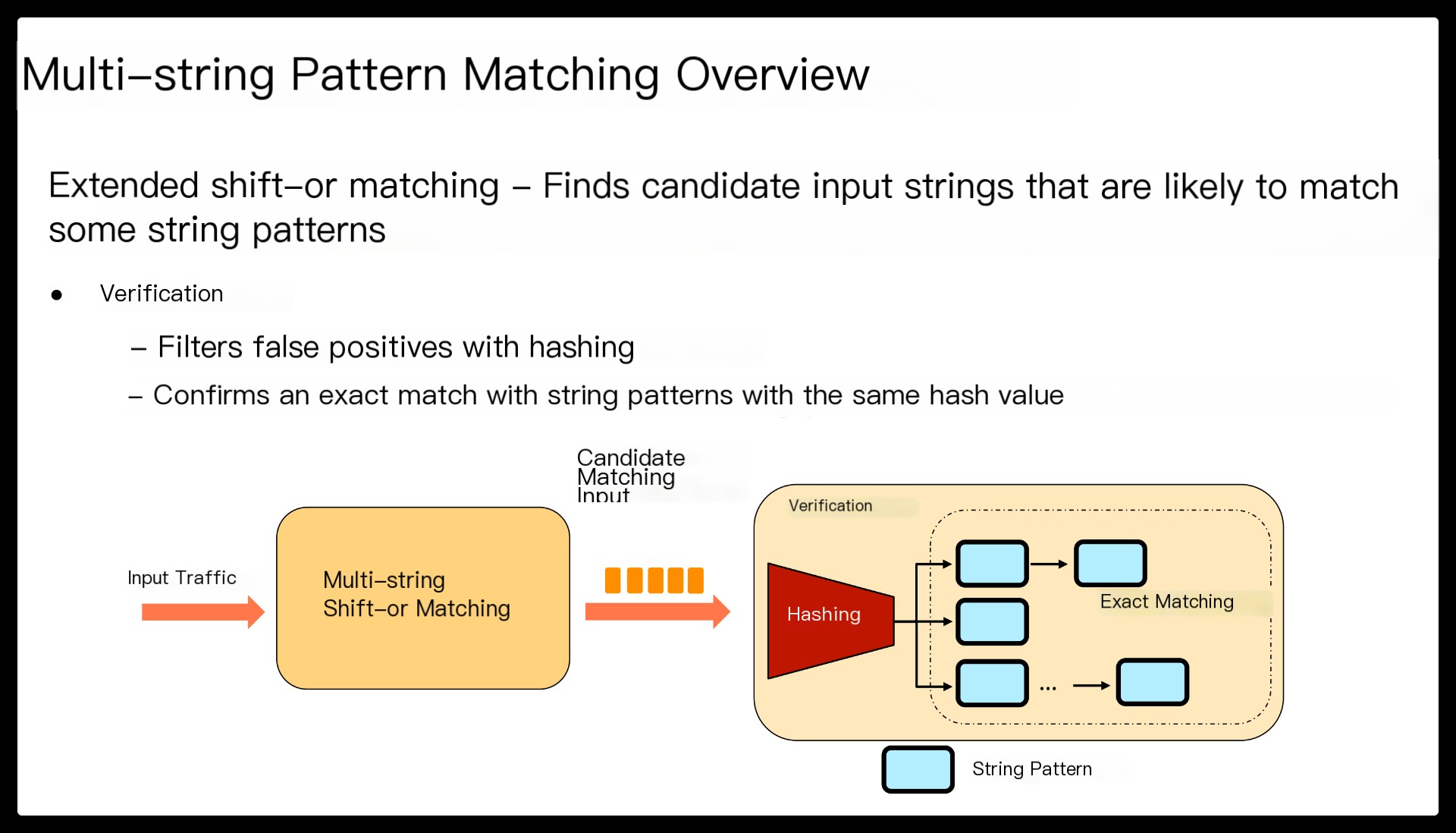
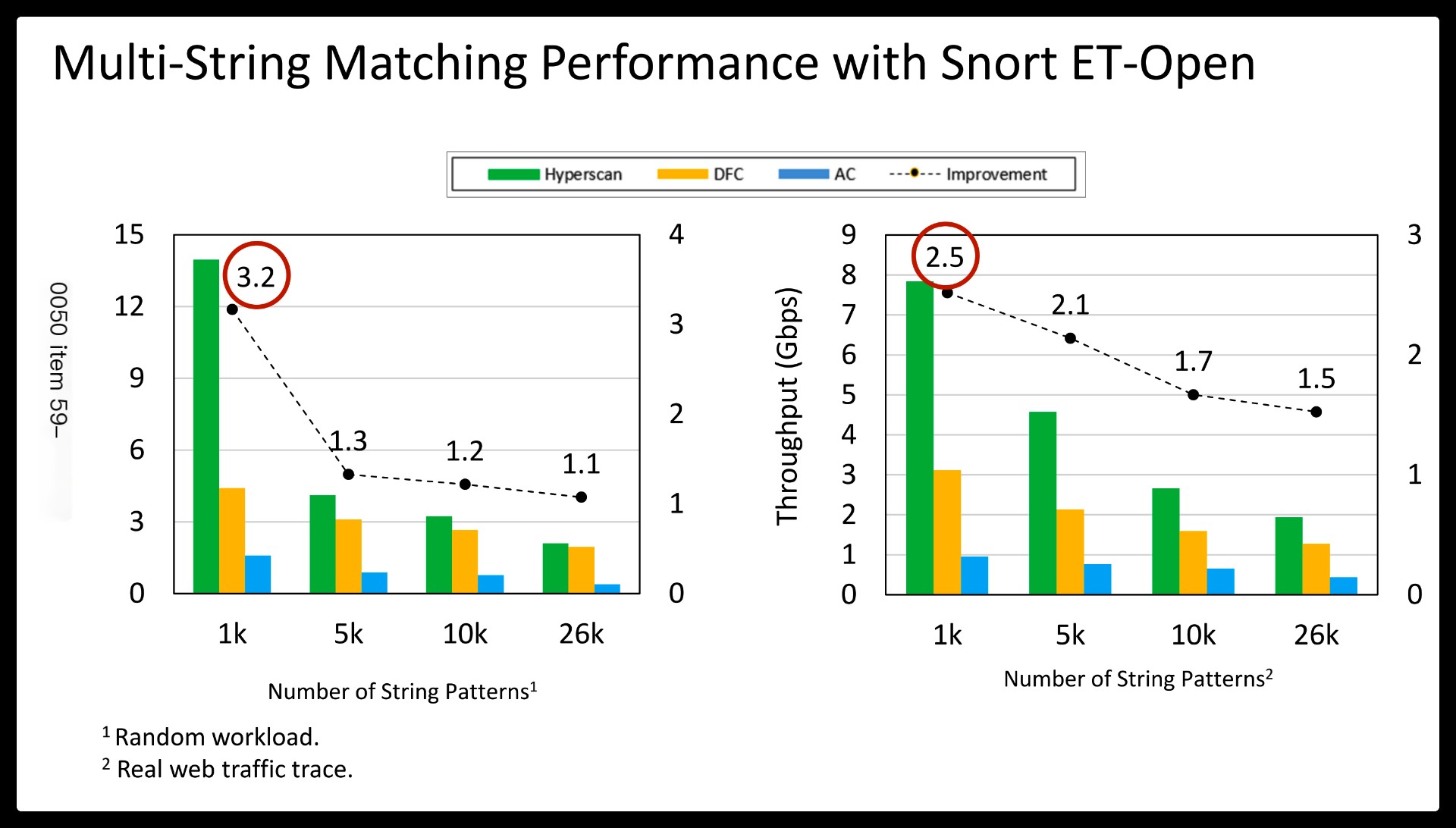
Despite continued efforts, the performance of regex matching on a commodity server still remains impractical to directly serve today’s large network bandwidth. Instead, the de-facto best practice of high-performance DPI generally employs multi-string pattern matching as a precondition for expensive regex matching.
This hybrid approach (or prefiltering) is attractive as multi-string matching is known to outperform multi-regex matching by two orders of magnitude, and most input traffic is innocent, making it more efficient to defer a rigorous check. For example, popular IDSes like Snort and Suricata specify a string pattern per regex for prefiltering, and launch the corresponding regex matching only if the string is found in the input stream.
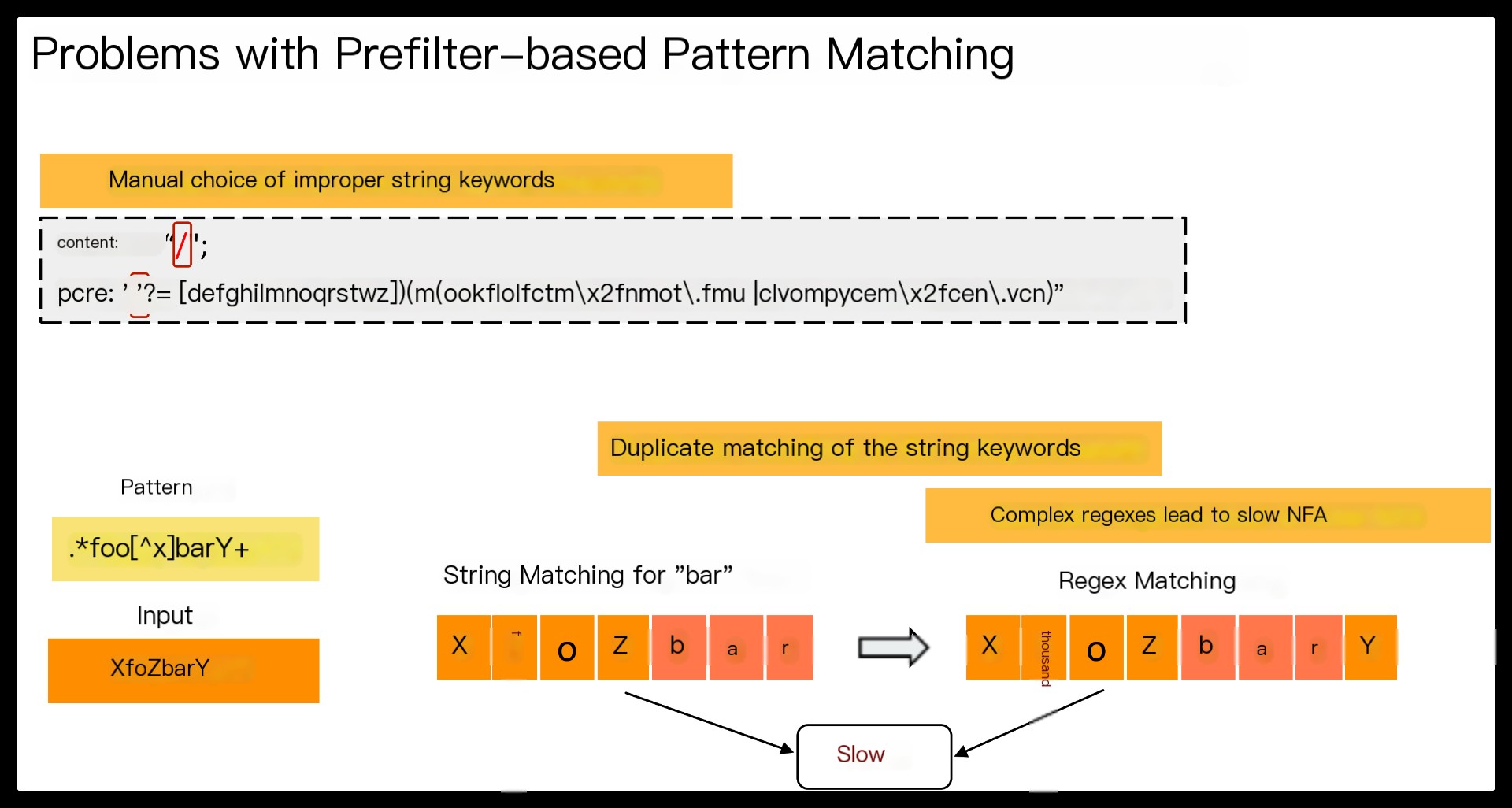
However, the current prefilter-based matching has several limitations.
First, string keywords are often defined manually by humans. Manual choice does not scale as the ruleset expands over time, and improper keywords would waste CPU cycles on redundant regex matching.
Second, string matching and regex matching are executed as two separate tasks, with the former leveraged only as a trigger for the latter. This results in duplicate matching of the string keywords when the corresponding regex matching is executed.
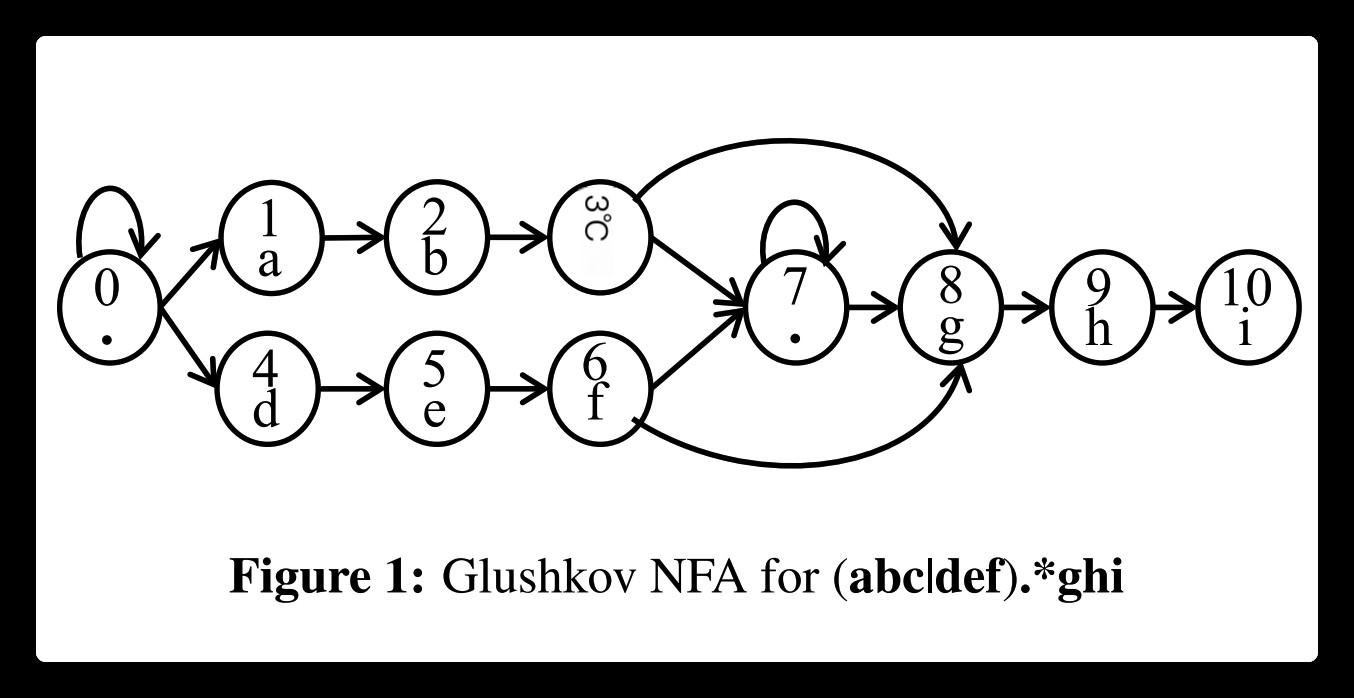
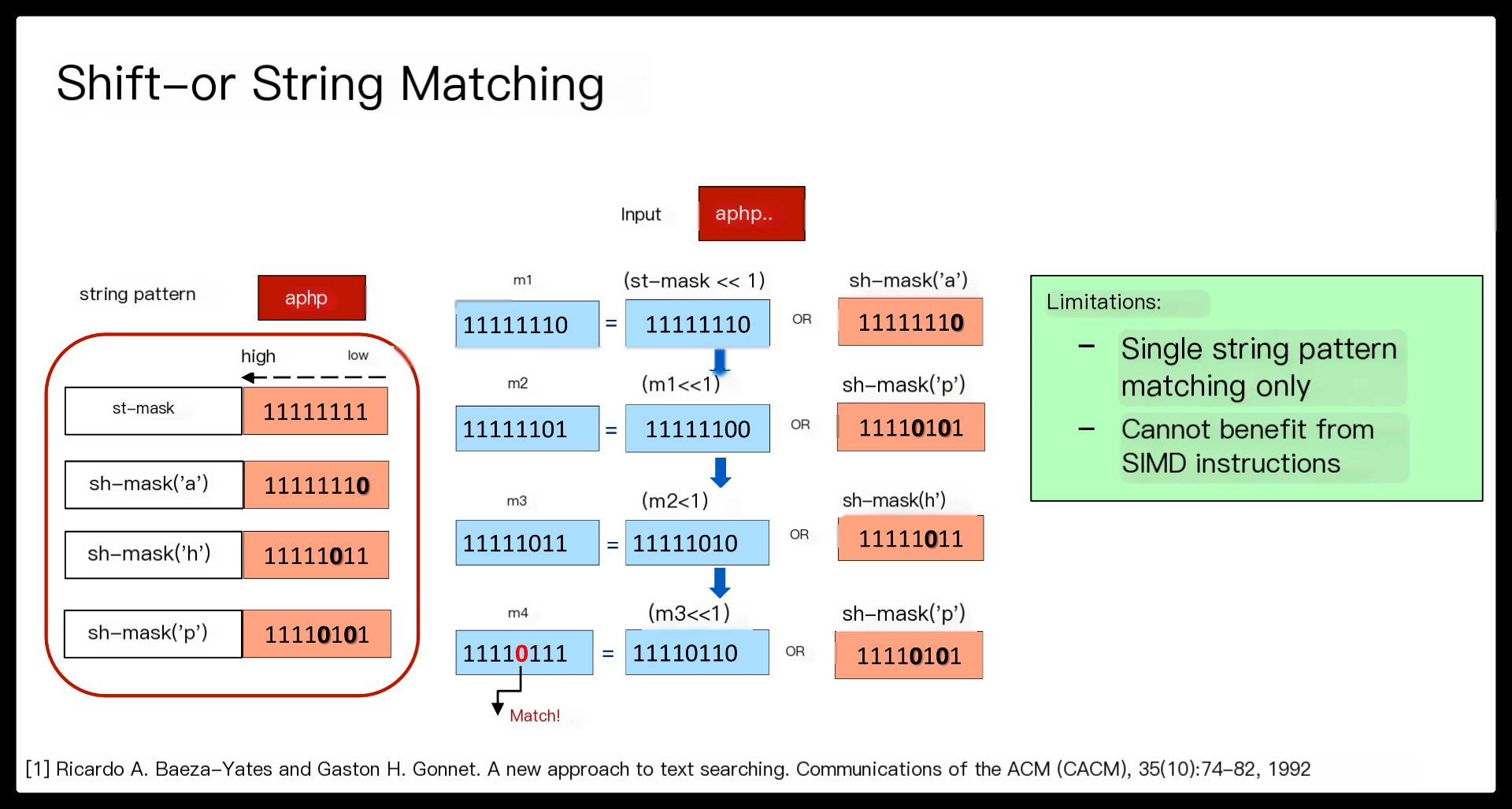
Third, current regex matching typically translates an entire regex into a single finite automaton (FA). If the number of deterministic finite automaton (DFA) states becomes too large, one must resort to a slower non-deterministic finite automaton (NFA) for matching the whole regex.
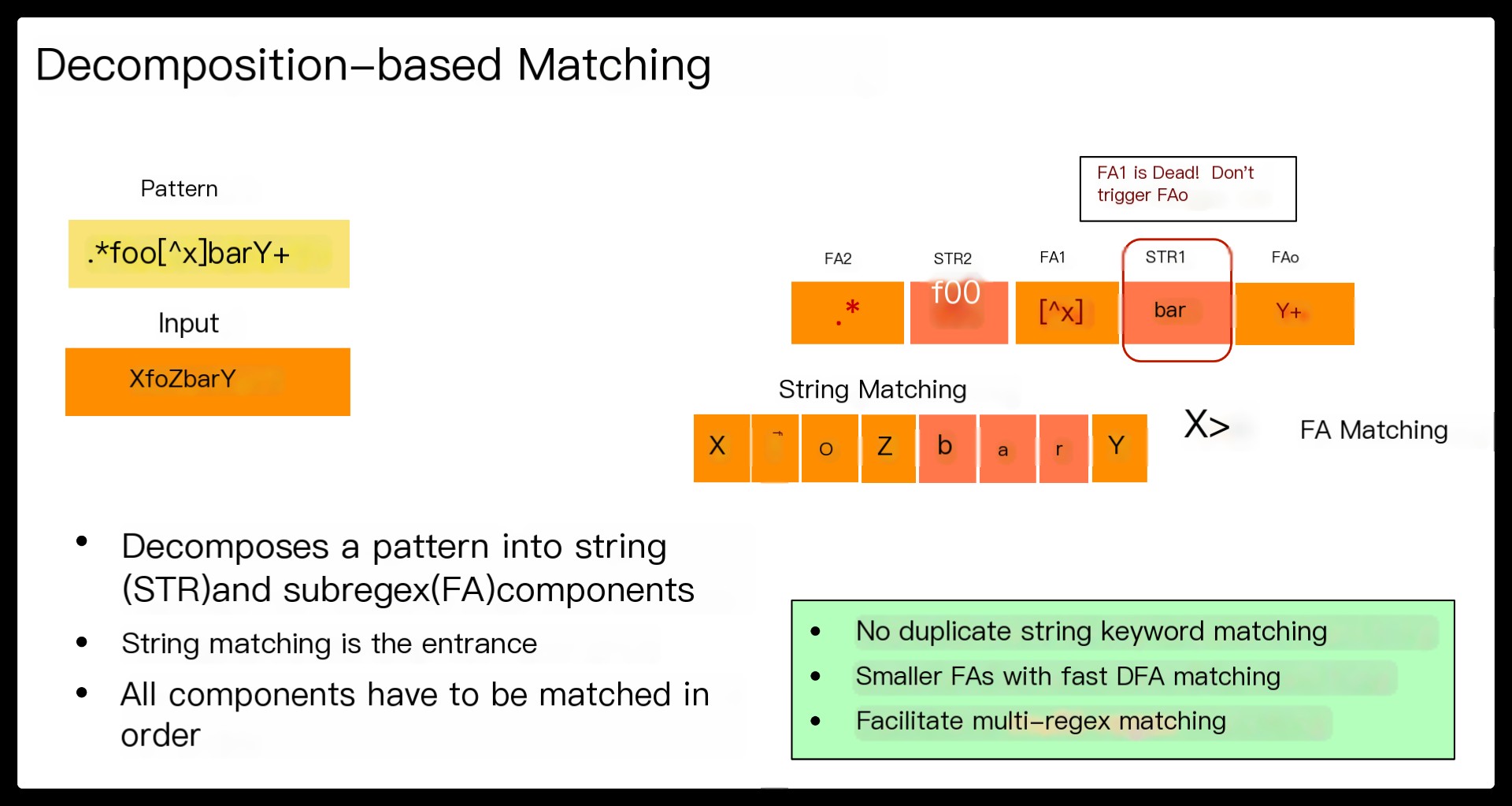
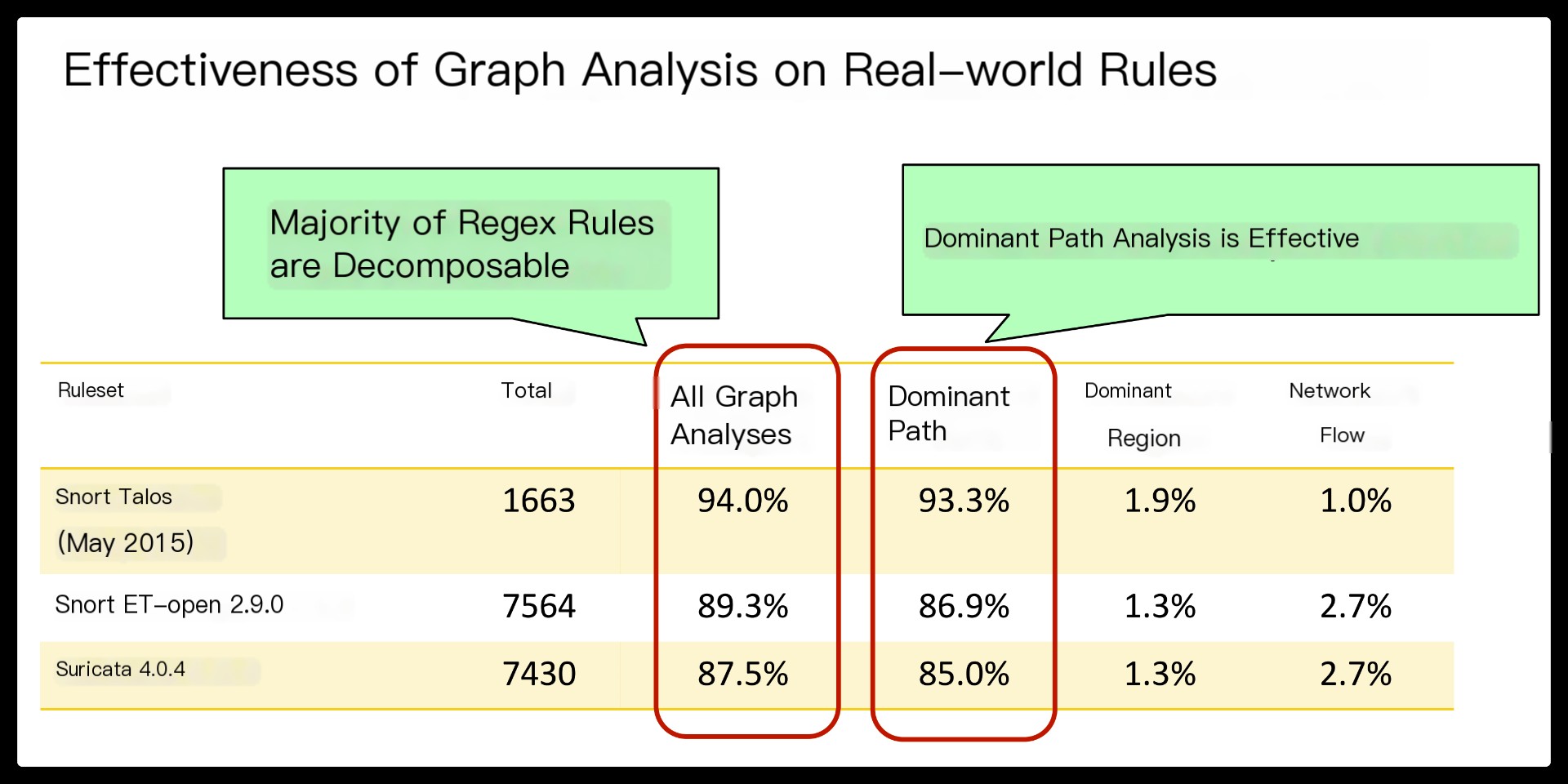
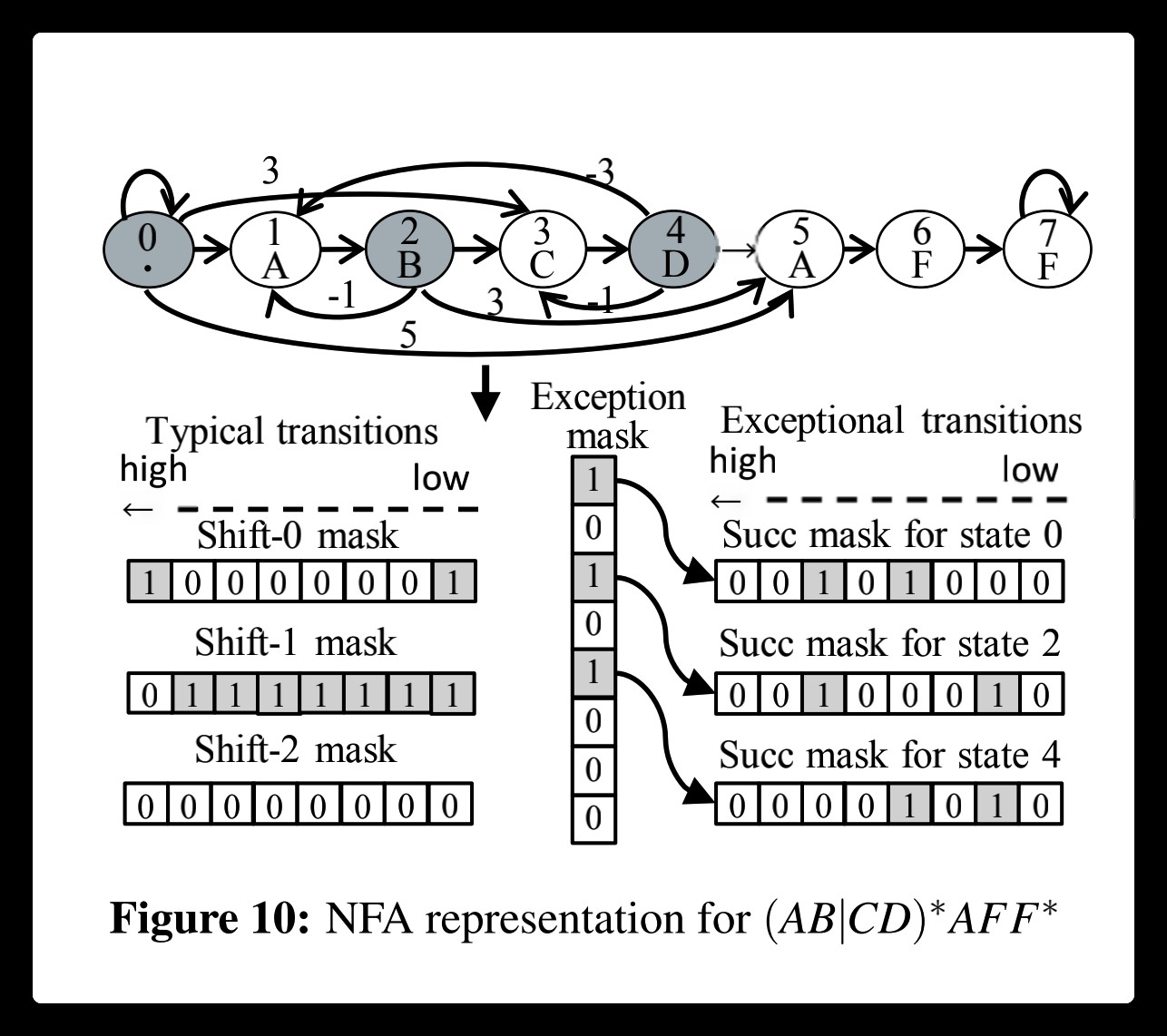
Hyperscan, a high-performance regex matching system that exploits regex decomposition as the first principle. Regex decomposition splits a regex pattern into a series of disjoint string and FA components.
This translates regex matching into a sequence of decomposed subregex matching whose execution and matching order is controlled by fast string matching.
This design brings several benefits.
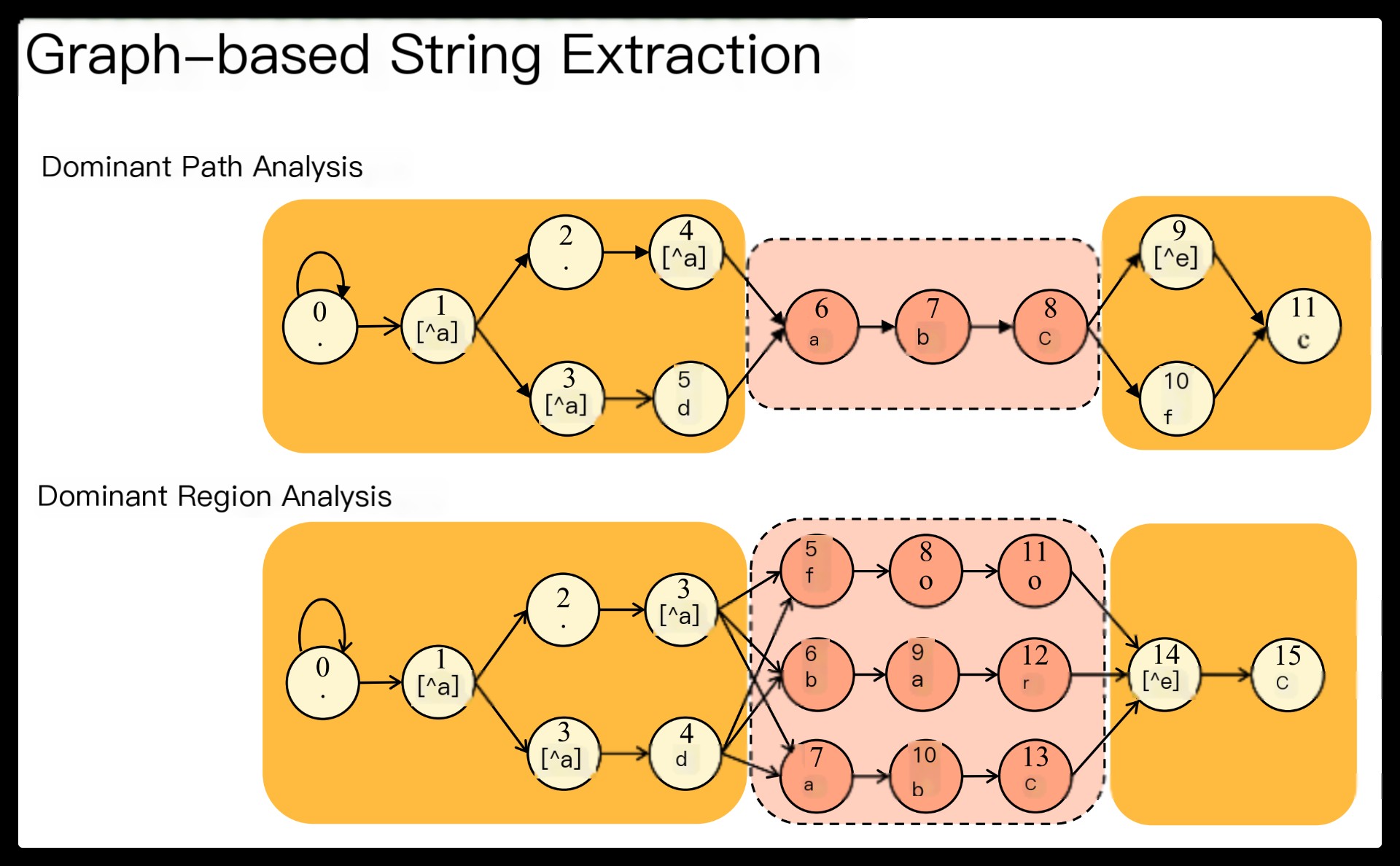
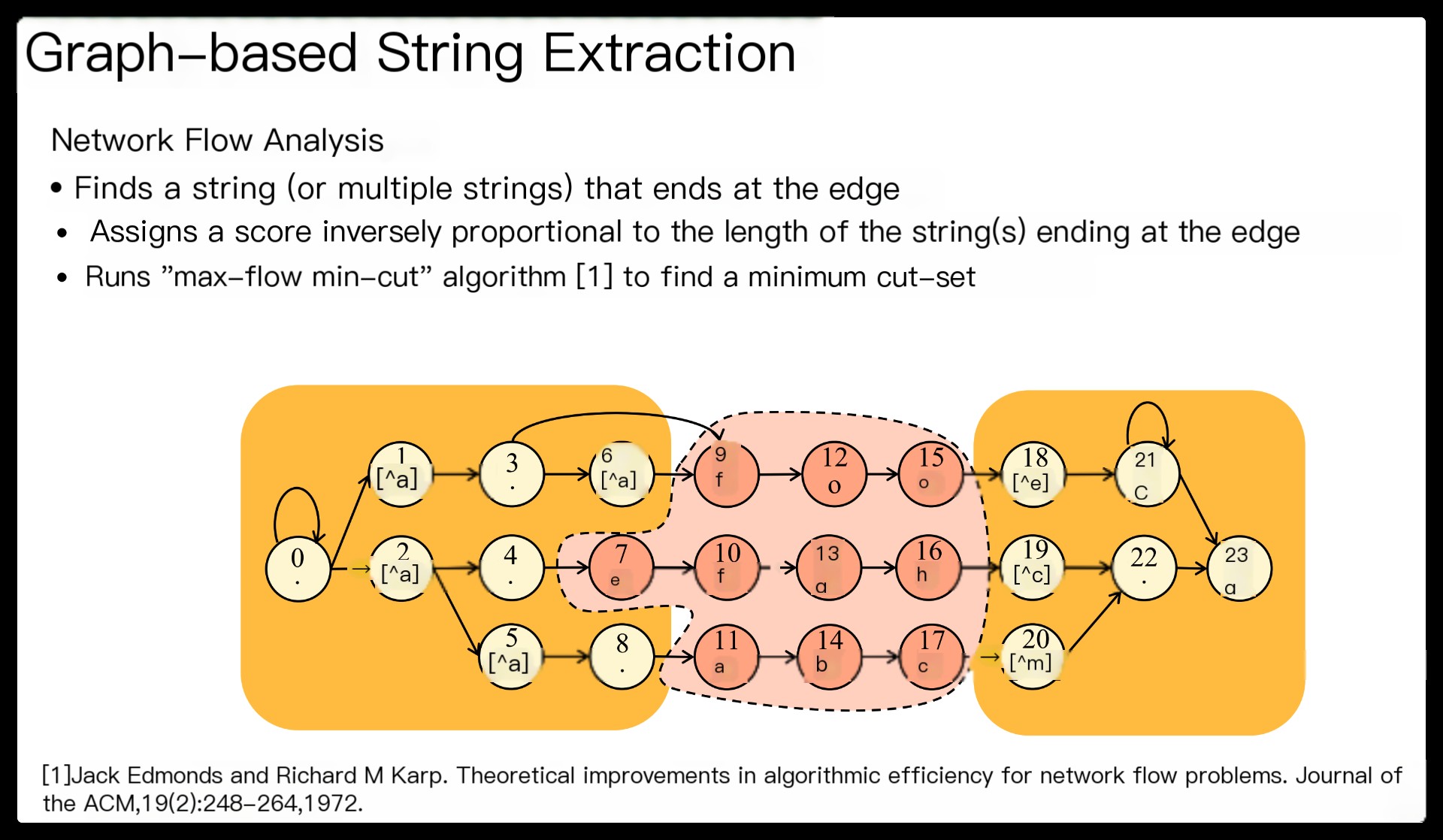
First, our regex decomposition identifies string components automatically by performing rigorous structural analyses on the NFA graph of a regex. Our algorithm ensures that the extracted strings are prerequisites for the rest of the regex matching.
Second, string matching is run as a part of regex matching rather than being employed only as a trigger. Unlike the prefilter-based design, Hyperscan keeps track of the state of string matching throughout regex matching and avoids any redundant operations.
Third, FA component matching is executed only when all relevant string and FA components are matched. This eliminates unnecessary FA component matching, allowing efficient CPU utilization.
Finally, most decomposed FA components tend to be small, so they are more likely to be converted to a DFA and benefit from fast DFA matching.


Beyond the benefits of regex decomposition, Hyperscan also brings a significant performance boost with single-instruction-multiple-data (SIMD) accelerated pattern matching algorithms.
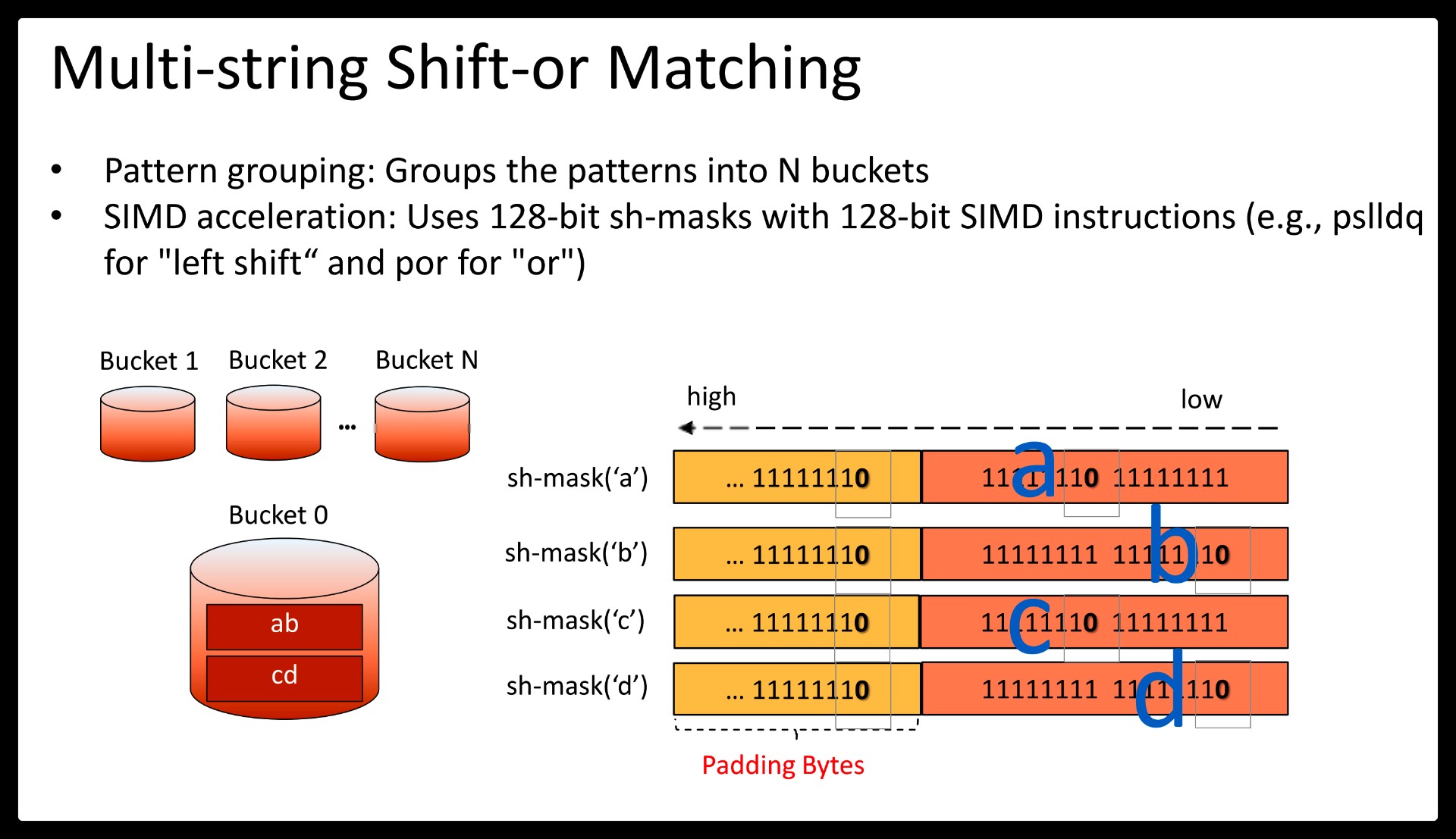
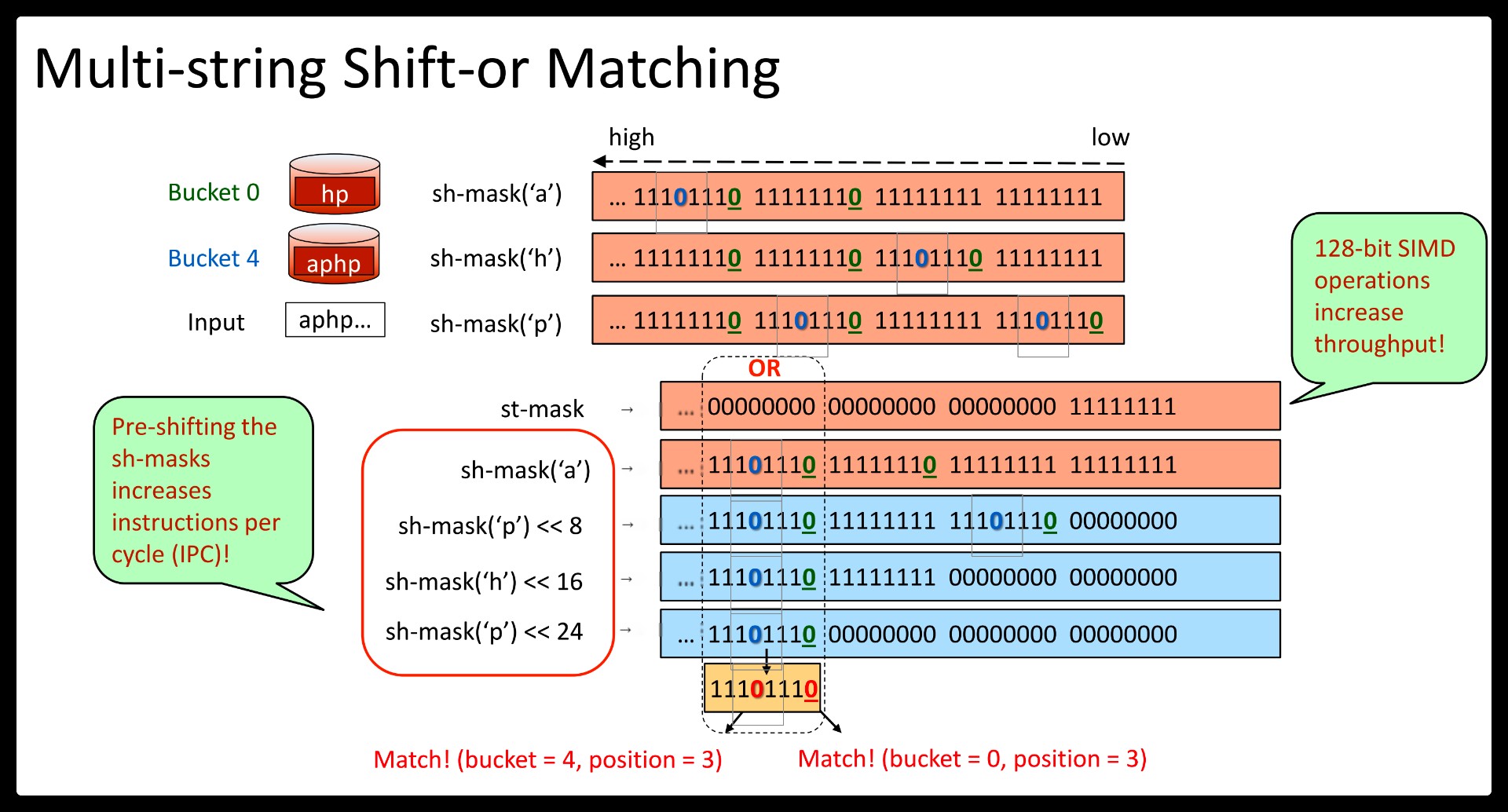
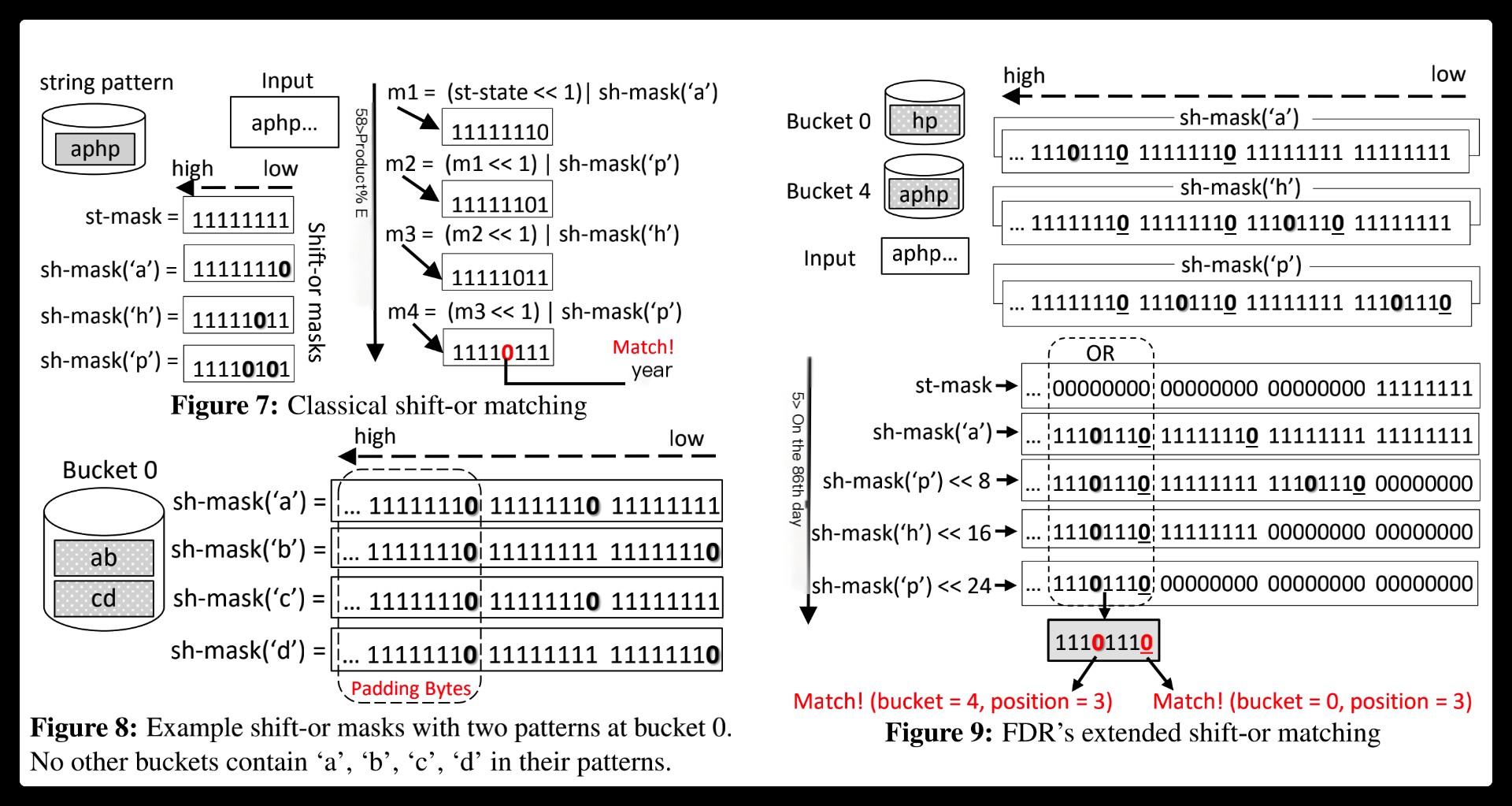
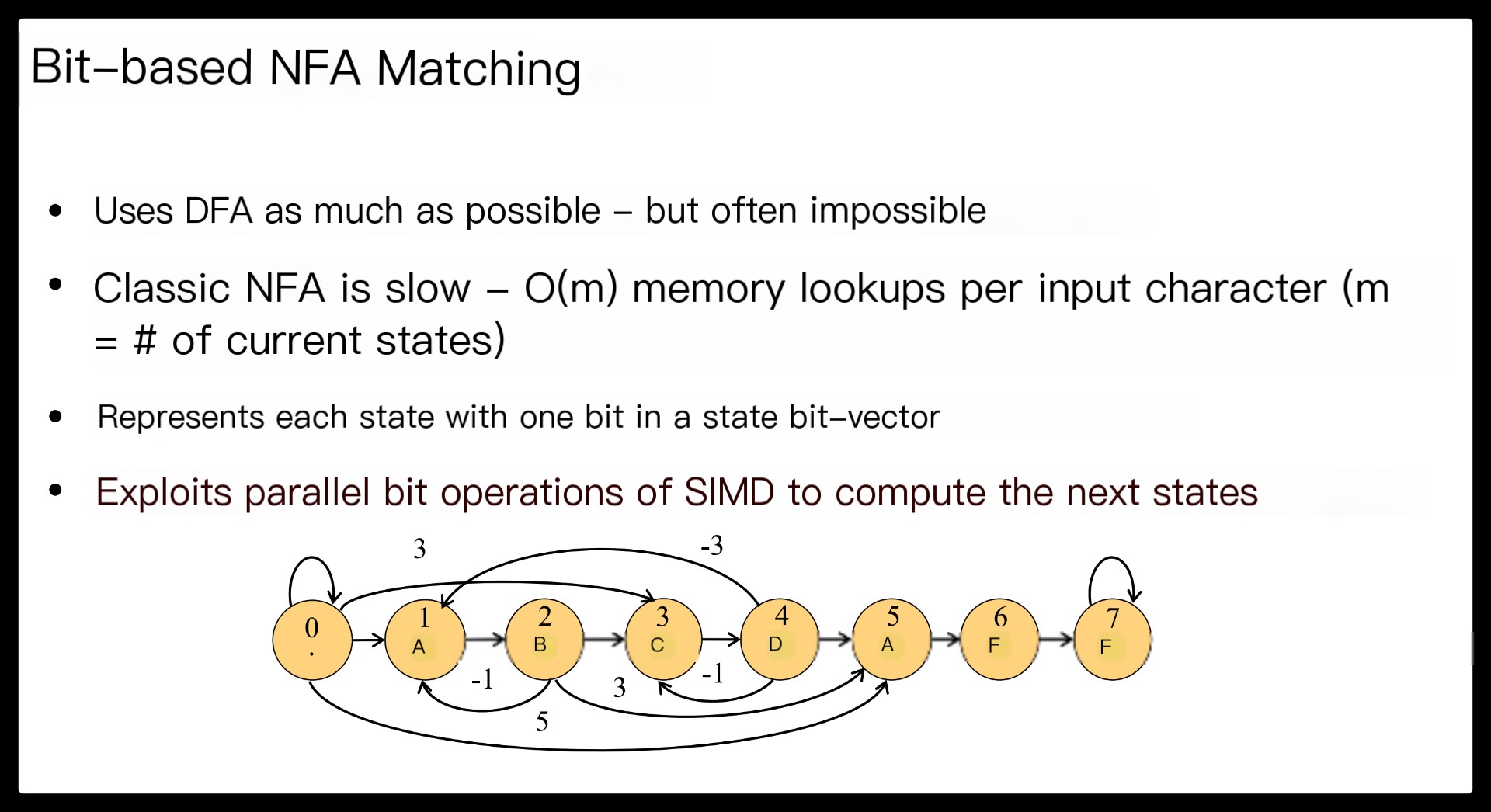



Source code at https://github.com/intel/hyperscan
References:
https://github.com/intel/hyperscan
Hyperscan is a high-performance multiple regex matching library. It follows the regular expression syntax of the commonly-used libpcre library, but is a standalone library with its own C API. Hyperscan uses hybrid automata techniques to allow simultaneous matching of large numbers (up to tens of thousands) of regular expressions and for the matching of regular expressions across streams of data. Hyperscan is typically used in a DPI library stack.
https://www.usenix.org/sites/default/files/conference/protected-files/nsdi19_slides_wang_xiang.pdf
https://www.usenix.org/conference/nsdi19/presentation/wang-xiang
https://www.usenix.org/system/files/nsdi19-wang-xiang.pdf
http://intel.github.io/hyperscan/dev-reference/getting_started.html#very-quick-start