

This article is contributed by Alex Converse, a video engineer at Twitch, for the San Francisco Video Technology Meetup 2019. His presentation focused on the origins of the SRT protocol and the transmission of real-time video streaming over UDP on challenging networks. He also introduced UDT, open source projects, and the SRT Alliance, providing a technical overview of SRT. Finally, he analyzed how SRT packets, SRT packet buffers, and Nak packets manage packet loss and latency issues.
Text by Alex Converse
Translation by Adrian Ng
 >
>
Hello everyone, I am a video engineer at Twitch, and tonight my presentation topic is the inside story of the SRT protocol. In the past, I’ve seen many wonderful talks about software decoders supporting SRT functions and its various potentials. However, today, I will pull back the curtain to see what’s behind the SRT protocol.
 >
>
This SRT (Secure Reliable Transport) is not that SRT (SubRip Subtitle: a subtitle format). This video transport protocol enables live streaming under challenging network conditions. It is based on UDP unicast (one-to-one) and focuses on contribution rather than delivery. Additionally, it features sub-second tunable constant latency.
In simple terms, tunable means you can configure the protocol and adjust latency, allowing a trade-off between packet loss and delay. Once broadcast starts, the delay is locked in, preventing additional delay accumulation from varying network conditions. Furthermore, the system also provides content encryption.

Why do I find SRT interesting? We know RTMP is the de facto standard for live video on the public internet; but RTMP has been around for a long time, and its standard was abandoned after its last update in 2012. New codec standards like HEVC or AV1 typically lack RTMP standard support. Even if someone hacked these codecs’ support into RTMP, it doesn’t perform well on mobile networks.
SRT is gaining momentum as a potential replacement for RTMP. There are now over 250 members in the SRT Alliance, and at recent trade shows, almost every booth had an SRT Alliance member or an SRT-Ready sticker.
SRT functionality is virtually ready out of the box in VLC, Gstreamer, and Ffmpeg, and there are patches for tools like OBS Studio in progress. SRT originated from an older protocol called UDT. UDT was created in 2001 and still has a webpage on SourceForge, but its design goal was to transfer large files over public networks in the shortest time possible.

The developers of UDT submitted several drafts to the IETF to describe how UDT works. In total, there were four drafts, with the final IETF draft released in 2010. After that, the main developers of UDT continued working on this protocol for three more years, with the final version of its implementation remaining in 2013.
Haivision, an encoder supplier, adopted UDT and transformed it from a file protocol to a live video protocol. In 2013, they used it at the IBC conference primarily to demonstrate HEVC encoding.
After four years, they felt their proprietary protocol might not be the best way to create an interoperable ecosystem. So in 2017, they open-sourced SRT.

Haivision and Wowza co-founded the SRT Alliance to promote the development and adoption of SRT.
In early 2018, they released the v1.3.0 update of SRT. This was the largest alteration to the protocol since the initial open-source release. Also, its license was changed to MPL (Mozilla Public License); the file transfer mode was re-added.

In 2018, they also released the SRT Technical Overview, which is more like a specification. The document spans 89 pages, in contrast to the 52 pages for the RTMP spec. The document details various information, with even some competitors admitting the SRT specification is quite impressive.

From a high-level view, SRT uses a bidirectional UDP socket, allowing for data and control flow multiplexing over the same socket. As it doesn’t use TCP, SRT implements its own reliability, ordering, and congestion control. SRT uses selective retransmit to handle packet loss and builds its unique encryption system based on standard primitives (instead of DTLS).

SRT Data Payload supports fragmentable payloads. Practically, I’ve only seen it used with MPEG transport streams. The entire transport stream introduces SRT packets, where each transport stream packet has its own sync byte and transport stream header. I am sure these sync bytes combat packet loss and resynchronization.
Given a 1500-byte Ethernet MTU, if you attempt to fit in 188-byte packets, you’ll find there isn’t enough space for 8 TS packets, which is why 7 TS packets are used — leaving enough room for the SRT header.
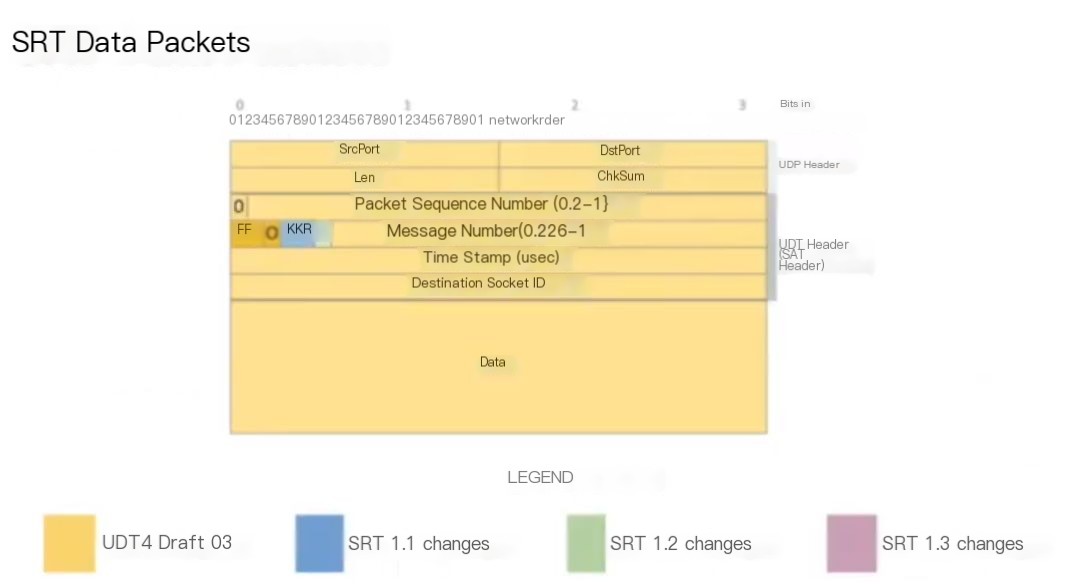
The image above presents an overview of the SRT packet layout. Initially, there is a UDP header, along with a UDT header, and indeed the SRT header is adapted from the UDT header.
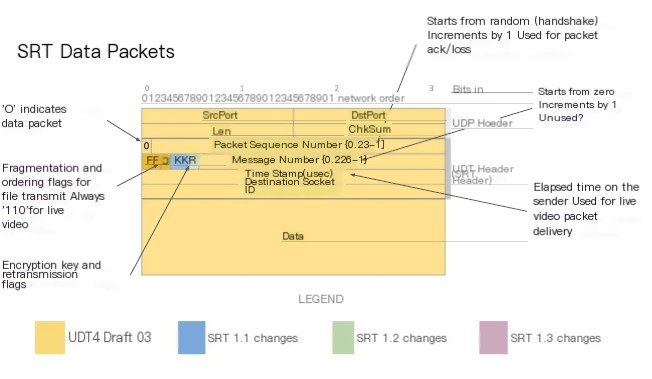
The first bit is 0, indicating it is a data packet, followed by a packet sequence number, starting from a random value determined during the handshake process, with each subsequent packet increasing by 1. This value is used for identifying packets, packet acknowledgments, and packet loss messages. There is a message number, beginning at 0, which increments with each message in my video, but it seems to serve little purpose, what’s going on here?
You can see a timestamp measured in microseconds, representing the sender’s elapsed time. The receiver uses this packet to play it from the SRT buffer downstream to the TST MUX RN video decoder. This real-time video segment and sequence is always “1 1 0”. 1 1 refers to standalone numbering, and message numbering is for messages fragmented across multiple packets. But in real-time video mode, we only need to fill the TS as much as possible, which we call standalone messages.
Under the Ordering flag, two flags are encryption and retransmission flags; if something goes wrong, the ordering flag can deliver information out of order. The encryption flag will alert you to which key is in use, and the retransmit flag indicates whether this is a first-time send or a retransmitted step. Retransmitted packets typically retain the original sequence number, message number, and timestamp.
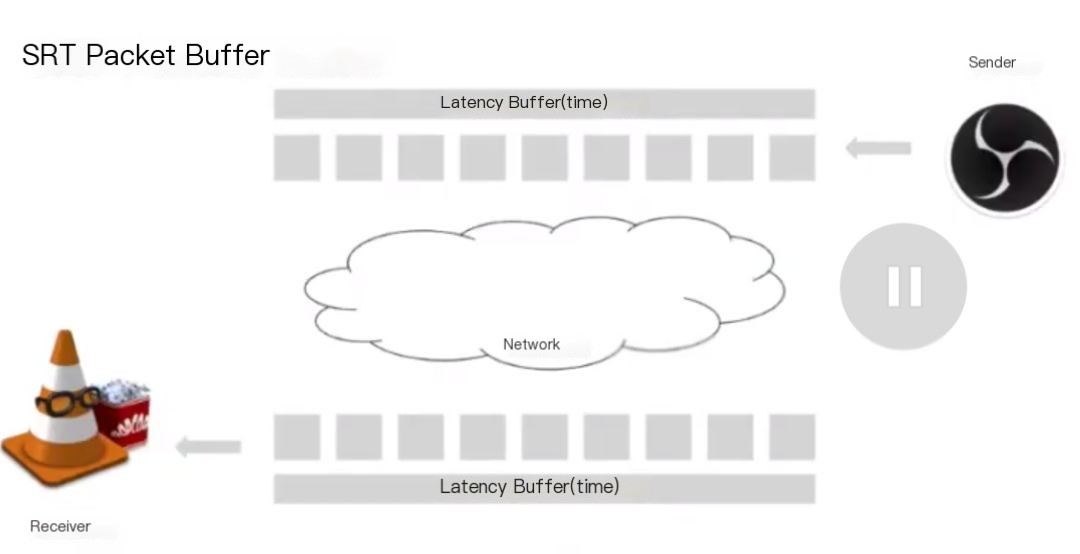
The core idea of SRT is that both the sender and receiver agree on a latency buffer period and try to synchronize content as packets start streaming out of the receiver. Currently, VLC supports off-the-shelf SRT, and OBS has a patch for SRT. The sender creates packets and places them in the delay buffer because it takes time for the packet to reach the receiver in the network.
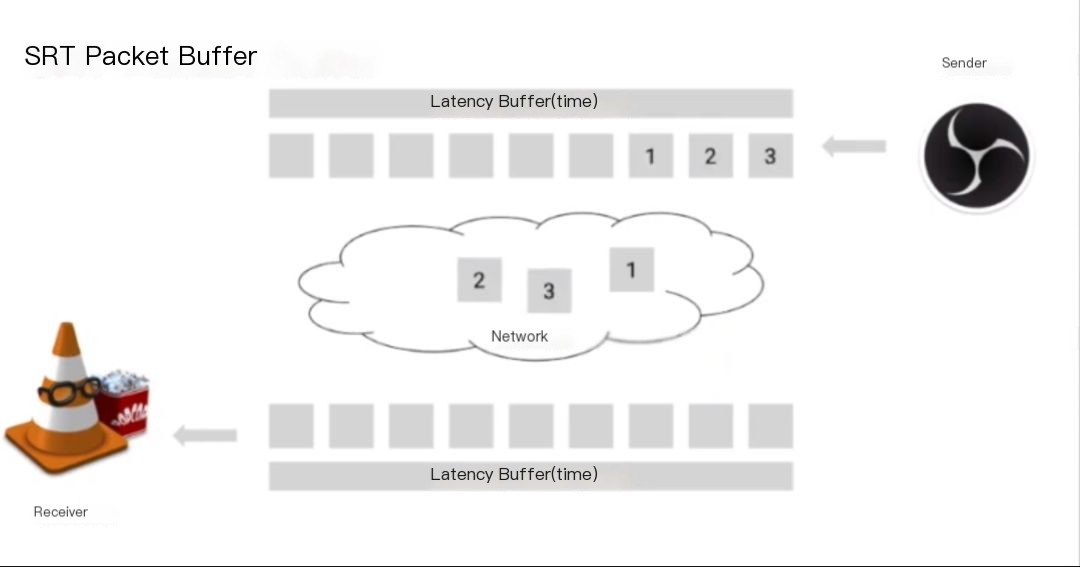
The sender continuously generates packets, and the receiver ultimately receives these packets. The sender continues to generate, and the receiver keeps receiving. And so on.
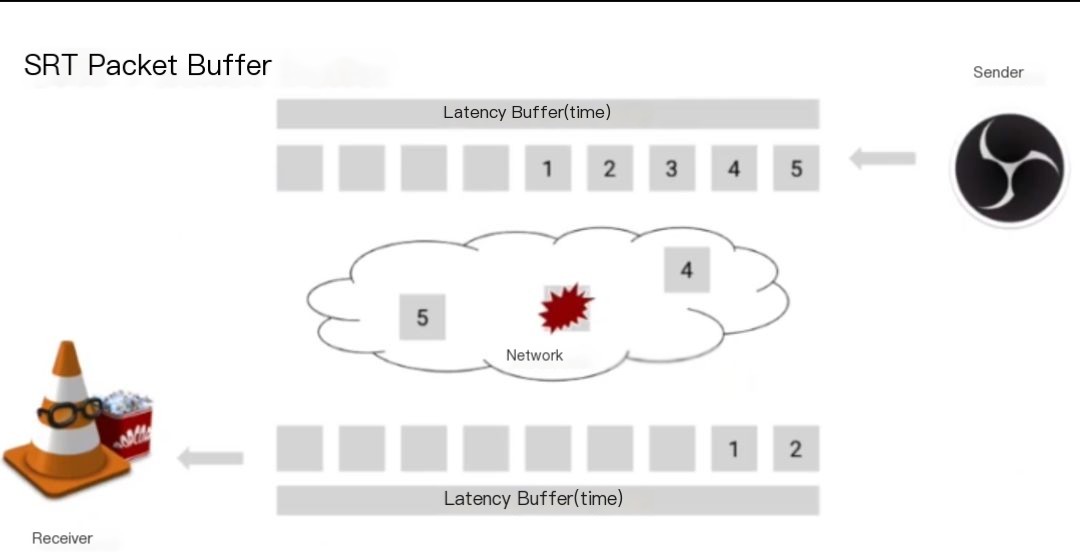
This showcases an unfortunate situation—packet 3, shown in the image above, has been lost. So far, no one has noticed any data discrepancy. Was expecting packet 3, but instead received packet 4, which immediately generates a negative acknowledgment packet, placing packet 4 in the buffer, leaving a gap (hole) for packet 3.
The sender continues distributing packets until the next packet arrives. Suddenly, the sender receives a NACK, realizing that the receiver missed packet 3 because the sender retained previously sent packets in the buffer. As a result, the sender retransmits packet 3, and continues generating packets; the receiver continues receiving packets. Note, at this point, the sender’s buffer is now filled with packets.
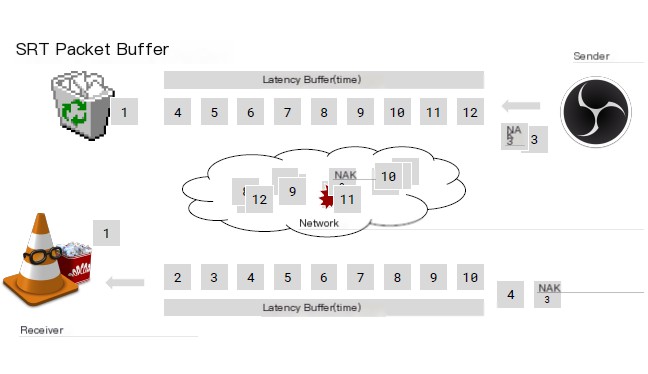
Packet 1 is expelled, discarded. Finally, the receiver receives packet 3, promptly filling the previous gap (hole), and operations resume normally. The receiver’s buffer ultimately fills with the specified packets, and subsequently, packet 1 is fed to the TS demuxers and decoders.
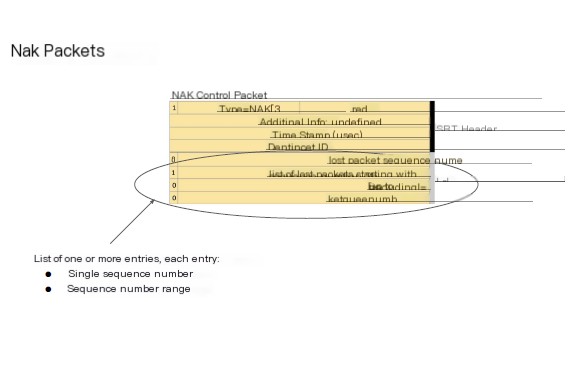
This is the representation of Nak in the protocol overview. First is the SRT header, as it is a control packet it starts with a 1, followed by the list of lost packets.
Each loss list contains one or more entries. Each entry is either a single packet or a range, where you might, in one message, indicate you lost packet 5, 9, and all packets from 11 to 15.
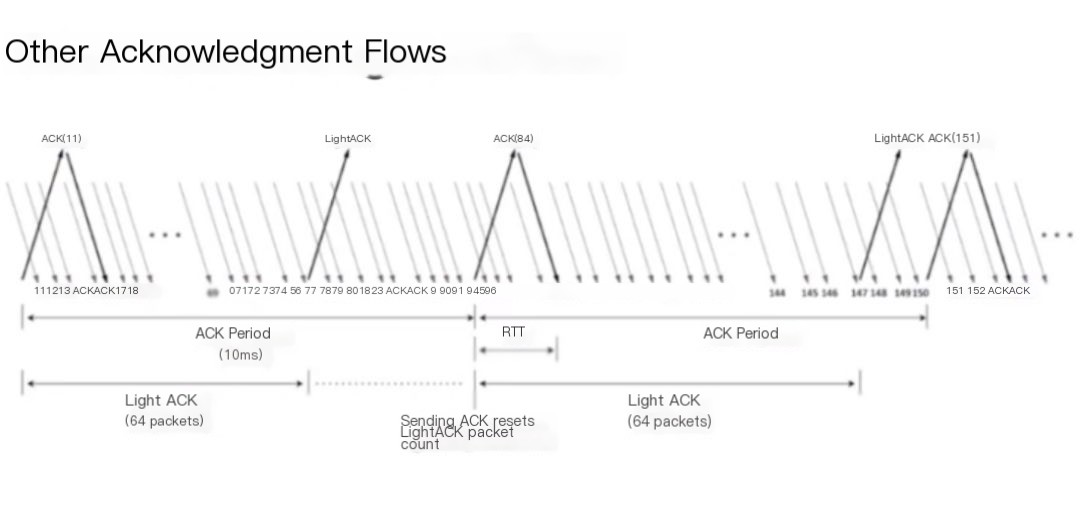
Besides negative acknowledgment, SRT also has positive acknowledgment. The receiver sends an acknowledgment every 10 milliseconds. With each ACK received, the sender immediately acknowledges it in response to the previous ACK, allowing you to estimate the round-trip time. If the rate of confirmation exceeds 64 packets, the receiver sends a lightweight acknowledgment. This Ack will not be re-confirmed and doesn’t include metadata types accepted by the Ack.
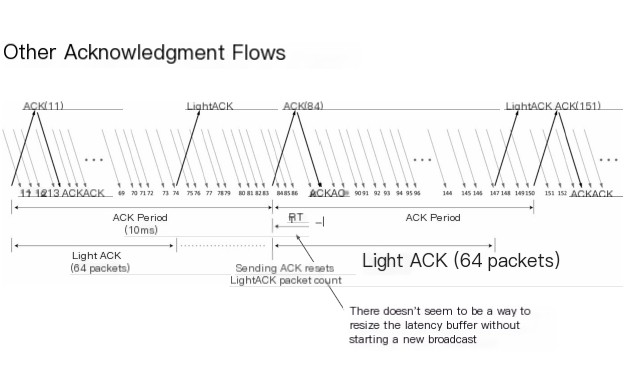
RTT is somewhat peculiar because there seems to be no way to adjust the latency buffer size without launching a new broadcast, leading to some limitations in broadcast scenarios.
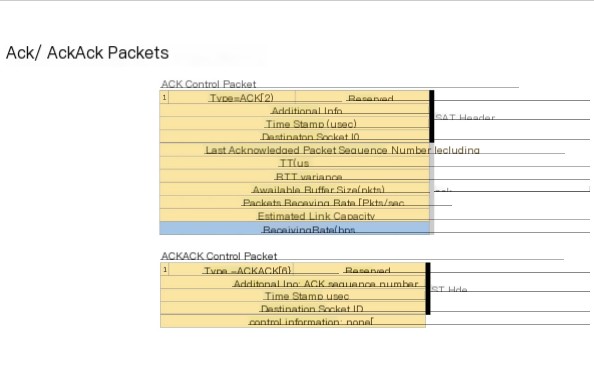
These are the Ack/AckAck packets displayed in the acknowledgment packet. Most importantly is the sequence number of the last received packet, as well as the round-trip time, round-trip time variance, buffer statistics like available size and packets, packet reception rate, and data reception rate. In lightweight Ack, you only receive the sequence number, and the acknowledgment of the Ack will reveal which Ack it is confirming, helping you to make deductions at the correct timestamp.

We all know a handshake is quite simple. In this GIF, Bill Maher continuously misreads Snoop Dogg’s gestures, and Snoop Dogg continuously attempts to sync with Bill, an example of body language misinterpretation. I think it’s an apt metaphor for the SRT handshake process.
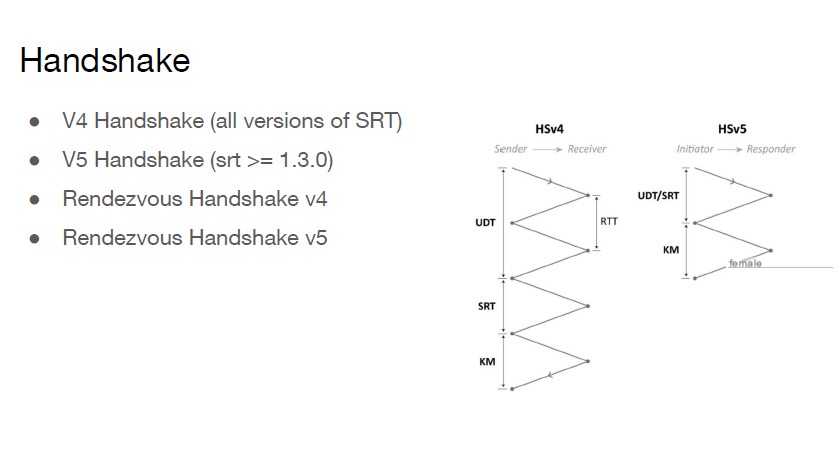
SRT has four handshakes between the sender and receiver (due to backward compatibility, all versions support it). The rendezvous handshake in v4 and V5 is quite special and won’t be explained in this discussion.
The biggest difference between v5 and v4 is the number of exchanges required. There are four round-trips in v4 and only two in v5.
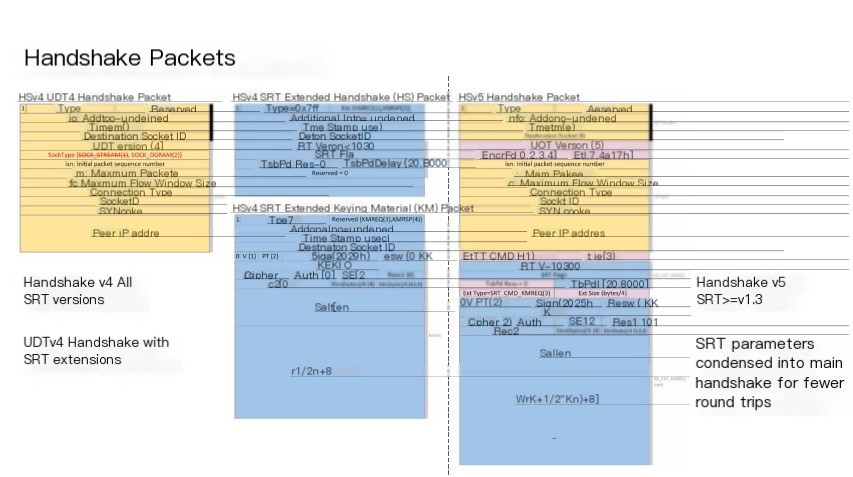
The diagram shows packet layout. The core idea is that v4 on the left uses unmodified UDT packets with SRT extensions, followed by an SRT handshake packet containing the required latency and initial sequence number, followed by key material for encrypting data payloads, while v5 on the right further combines (smushes) this information into a single packet (indicating that V5 directly modified the original UDT packet layout).

Subsequently, we will see both parties attempting a v5 handshake, where the initiator creates a handshake induction packet.
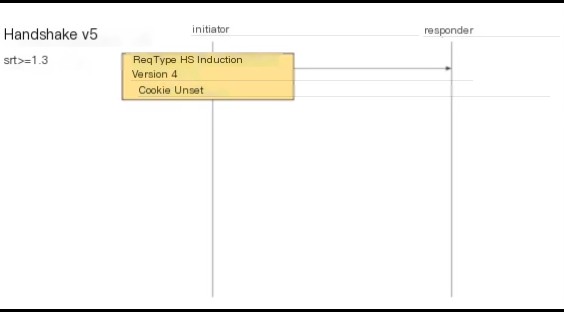
Its version number is set to 4, but the cookie field isn’t set, prompting the initial end to obtain the cookie shortly, relieving the responder from processing garbled packets but requiring parsing its packet to send something back. In practice, upon receiving the packet, the responder creates a version 5 induction packet and sets the cookie.
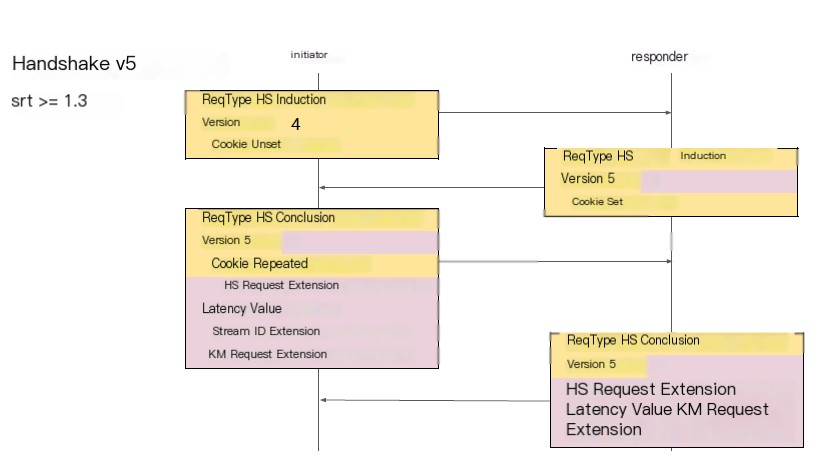
At this point, a v4 initiator will ignore v5 and continue to fill out v4 and repeat the cookie. However, if the initiator runs through v5, it will fill in the v5 program in the version field, along with SRT handshake extension values including latency values.
Initiator generates the stream ID possibly in the second handshake packet, first filling out the encryption handshake, and then responder responds using the latency value and crypto handshake.

The Stream ID, optional identifier sent in the second packet of the handshake because the first packet could get lost. This contains an application-specific parameter to notify you what the initiator intends.
This creates some contrast with RTMP, where in RTMP, you perform a TCP handshake and an RTMP handshake. Then, after bandwidth estimation, you call a set of RPCs to set up RTMP media streams.
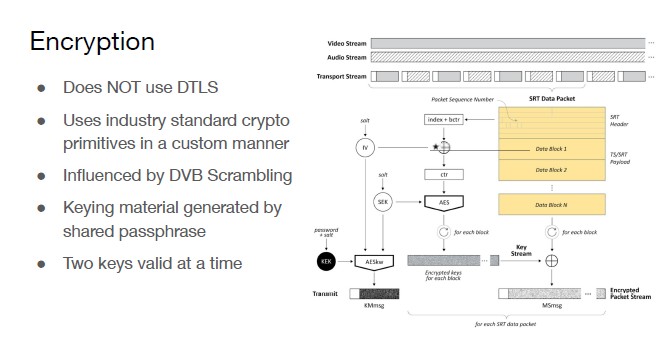
I mentioned earlier that SRT doesn’t use DTLS. It uses industry standard primitives in a custom method, heavily influenced by DVB scrambling. DVB is a European broadcast standard, and key material is generated by a shared passphrase. With these retransmissions and key rotations, two keys are valid at a time. You have an even key and an odd key, alternating between them, updating as you go. If you get a retransmission, you could reference the old key.

A small annotation in the specification says: ‘Hey, full packet encryption might look like the safest choice, but in practice, encrypting the header is a bit brittle against brute force. The initial MPEG TS sync byte may be designed not to encrypt the TS header. Indeed, we might attempt fast key rotation to achieve stronger encryption.’
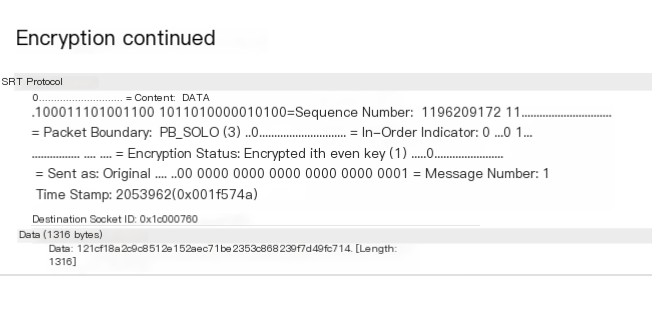
You can use Wireshark to analyze packets, where you will have an encrypted packet, with the first byte of payload as 12 (hex). You might already know that if it’s an unencrypted TS sync byte, it would be 47 (hex).
If you want to further explore the protocol, you can visit the SRT GitHub repository, and the technical overview includes a Wireshark SRT parser.

If you want to learn more about the SRT ecosystem or have products or information about SRT, please visit srtalliance.org.