Hyperscan is Intel’s high-performance regular expression matching library, which runs on x86 platforms and supports Perl-compatible regular expression (PCRE) syntax, simultaneous matching of regular expression groups, and stream operations. It is released as open-source software under the BSD license. Hyperscan offers a flexible C API and several different modes of operation to ensure its applicability in real-world network scenarios. Furthermore, its focus on efficient algorithms and the use of Intel® Streaming SIMD Extensions (Intel® SSE) enables Hyperscan to achieve high matching performance. Applicable in scenarios such as deep packet inspection (DPI), intrusion detection systems (IDS), intrusion prevention systems (IPS), and firewalls, it has been deployed in global network security solutions. Hyperscan is also integrated into widely used open-source IDS and IPS products, such as Snort* and Suricata*.
Under the Hood
The workflow of Hyperscan can be divided into two parts: compile time and runtime.
Compile Time
Hyperscan comes with a regular expression compiler written in C++. As shown in Figure 1, it takes regular expressions as input. Based on the features of the available Intel® architecture platform, user-defined patterns, and pattern characteristics, Hyperscan generates the corresponding pattern database through a complex process of graph analysis and optimization. The generated database can also be serialized and stored in memory for future runtime use.
Learn more about Intel DPDK and VPP-related knowledge, feel free to follow us:
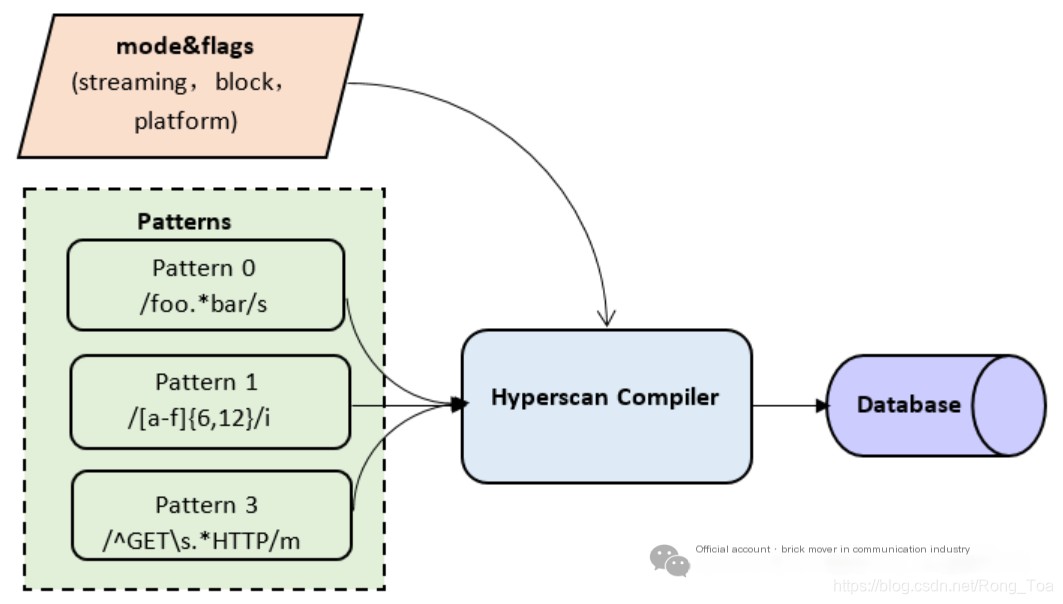
Figure 1: Hyperscan Compilation Process
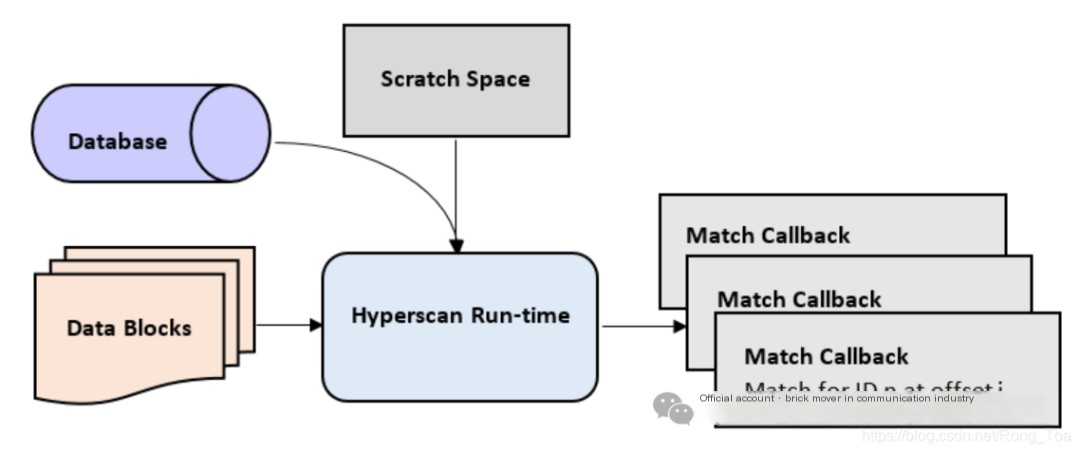
Figure 2: Hyperscan Runtime
Runtime
The Hyperscan runtime is developed in C. Figure 2 shows a high-level block diagram of the main components of the runtime. You need to pre-allocate a scratch space for temporary information used during scanning, and then call Hyperscan’s scanning API with the compiled database to trigger the internal matching engines (non-deterministic finite automata (NFA), deterministic finite automata (DFA), etc.) to match the corpus. Hyperscan accelerates these engines using single instruction, multiple data (SIMD) instructions provided by Intel processors and passes matches to user applications through user-provided callback functions for processing. Since the Hyperscan pattern database is read-only, users can share the database across multiple CPU cores or threads to enhance match scalability.
Features
Versatile Capabilities
Hyperscan supports cross-compilation for multiple Intel processors and is specifically optimized for different instruction sets. It has no operating system restrictions and simultaneously supports virtual machine and container scenarios, covering most PCRE syntax and supporting complex expressions including syntax like “.*” and “[^>]*”. Offering different operational modes (stream, block, and vector) to meet the needs of different scenarios, Hyperscan can find the start and end positions of matching data in an input stream if requested by using each pattern’s flags. For more details, please refer to the current version of the Hyperscan Developer Reference Guide.
Massive Matching
Based on complexity, Hyperscan can support matching a vast number of rules. Unlike most conventional matching engines, Hyperscan supports multi-pattern matching. Once a unique ID is assigned to each rule, Hyperscan can compile the rules into a database and output all currently matching rule IDs during the match process.
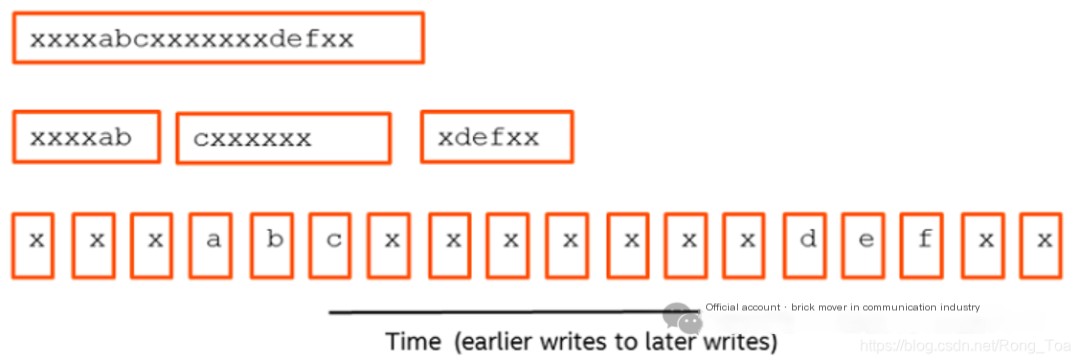
Figure 3: Data Spread Across Different Units Over Time
Streaming Mode
Hyperscan supports three operational modes: block mode, streaming mode, and vector mode. Block mode is the most straightforward, scanning a single contiguous block of data and returning matches to the caller when found. Streaming mode is designed for network scenarios where the data to be scanned is divided into multiple packets, allowing cross-packet matching. In streaming mode, Hyperscan can save the match state of the current data block and use it as the initial match state when a new data block arrives. As shown in Figure 3, regardless of how the “xxxxabcxxxxxxxdefx” data is split into packets over time, streaming mode ensures the consistency of the final match. Additionally, Hyperscan can compress the saved match state to reduce the application’s memory footprint. Streaming mode operation provides a simple way to scan data arriving over time without buffering and rescanning packets or restricting scanning to a fixed window of historical data. Finally, there’s vector mode, which provides sequential scanning of a set of non-contiguous data blocks in memory.
High Performance and Scalability
Hyperscan requires at least the Intel® Streaming SIMD Extensions 3 instruction set and utilizes SIMD instructions to accelerate matching performance. Below, we provide a brief summary of a publicly available performance demonstration, a performance analysis of Hyperscan with hsbench.
We used three different pattern sets for this analysis.
- Snort Literals is a set of 3,316 literal patterns extracted from an example ruleset included with Snort* 3 network intrusion detection system.
- Snort PCREs is a set of 847 regular expressions also extracted from an example ruleset containing Snort 3, taken from rules against HTTP traffic.
- Teakettle 2500 is a set of 2,500 synthetic patterns generated by a script that generates regular expressions with constrained complexity. We tested these pattern sets on alexa200.db, a large traffic sample built from a PCAP capture of an automated web browser browsing a subset of the top listings on Alexa*.
Figure 4 shows Hyperscan’s matching performance (Gbps) in block mode on an Intel® Xeon® Processor E5-2699 v4 @ 2.20 GHz.
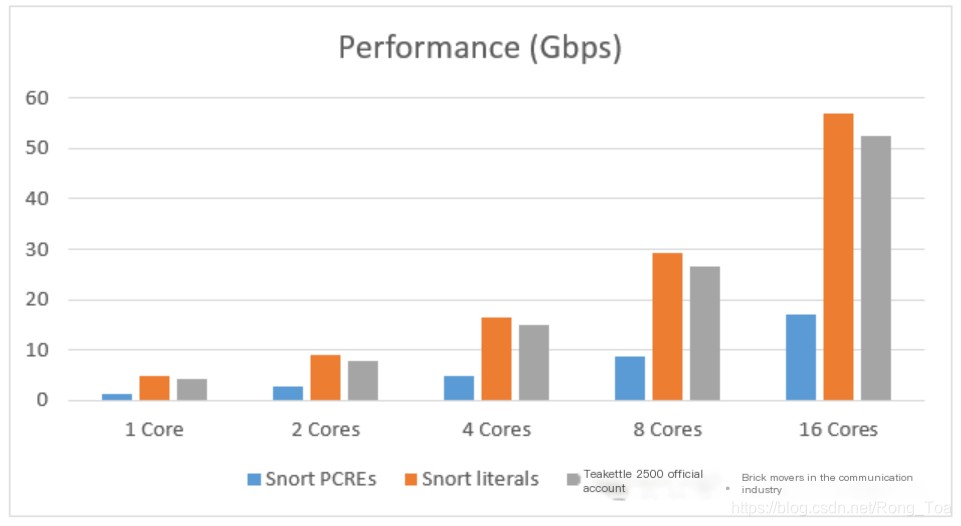
Figure 4: Hyperscan Performance in Block Mode on Different Rule Sets
Figure 4 demonstrates that Hyperscan can achieve good single-core performance using different rule sets. Furthermore, it exhibits high scalability, with its matching performance growing almost linearly with the number of cores used.
Integration of Hyperscan and DPDK
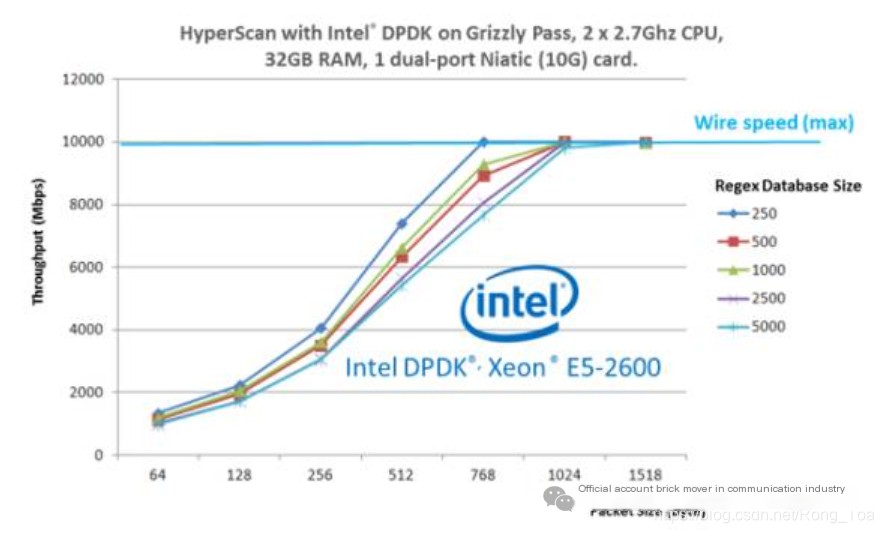
Figure 5: Performance of Hyperscan and Data Plane Development Kit Integration
The Data Plane Development Kit (DPDK) enables high-speed network packet processing and forwarding and is widely used in the industry. Hyperscan and DPDK can be integrated into high-performance DPI solutions. Figure 5 shows performance data of the integrated solution. In the tests, we used real patterns and HTTP traffic as input. The integration of Hyperscan and DPDK provides high performance, and in this test, performance can reach line rate at larger packet sizes.
Conclusion
Hyperscan provides a flexible, easy-to-use library that enables you to match a large number of patterns concurrently with high performance and good scalability, offering unique capabilities for network packet processing. The integration of Hyperscan with DPDK also provides a mature and efficient solution for DPI, IDS, IPS, and related products.