

ES Cluster High-Level REST Client Intermittently Encounters Cluster Access Timeout Issues: Diagnosis and Resolution
Background
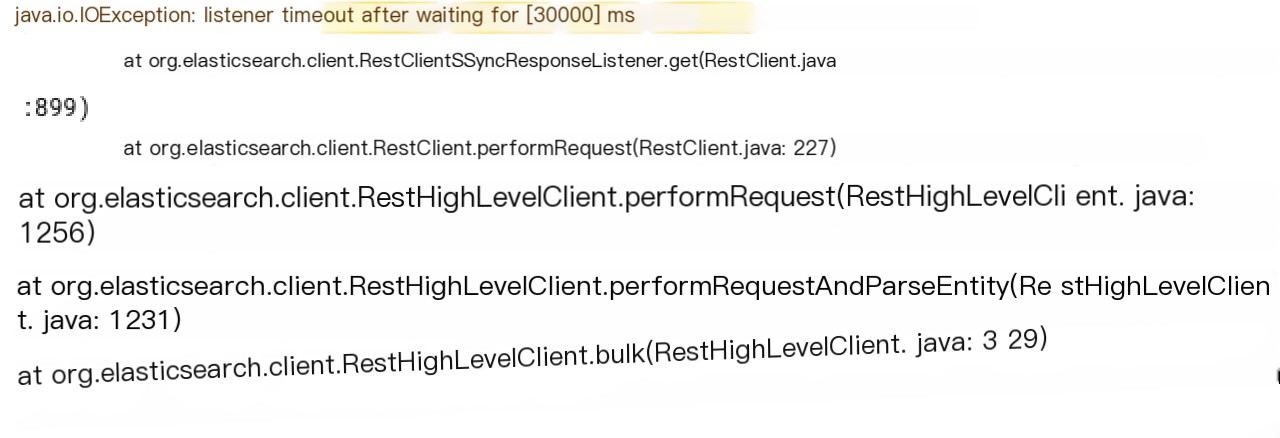
A client planned to use a cloud-based ES Cluster. After finishing the preliminary work, the cutover was performed overnight. A few hours later, the client reported that accessing the ES Cluster intermittently resulted in a “Connection reset by peer” or a “listener timeout after waiting for 30000 ms.”
 >
> >
>
Issue Diagnosis
The client was using the ES High Level Rest Client, with both the ES cluster and the client version being 6.8. The client reported that no issues were present before the cutover, and the timeouts appeared only afterward. The client suspected a relationship with the ES cluster. After investigation, it was discovered that the cluster’s CPU usage and load were relatively low, ruling out high load as a cause for the timeouts. Moreover, the connection reset by peer error occurs when the TCP connection is closed by the other end, suggesting the ES server might be actively closing connections?
Packet capturing was then deployed on all nodes in the ES cluster. Due to the large number of nodes and high traffic volume, we planned to capture traffic for two hours per node to see if any discoveries could be made. Wireshark was used to analyze the pcap files from the captures, and the captured TCP packets were all normal with no anomalies, which was puzzling.
Because the ES cluster exposed only a single VIP, which is the result of load balancing implemented through a VPC gateway, we contacted network colleagues to help troubleshoot this issue. The network team indicated that a connection reset by peer error from the client could only originate from backend RS, meaning the nodes of the ES cluster, because the VPC gateway, as a gateway, would not actively return a RST packet to the client. They advised deploying captures for RST packets on all ES cluster nodes to confirm.
As a result, packet captures were redeployed on all ES cluster nodes, capturing only RST packets:
tcpdump -i eth0 host x.x.x.x and port 9200 and 'tcp[tcpflags] & (tcp-rst) != 0' -vvv -w 1_rst.pcapAfter running overnight, we finally captured an RST packet:
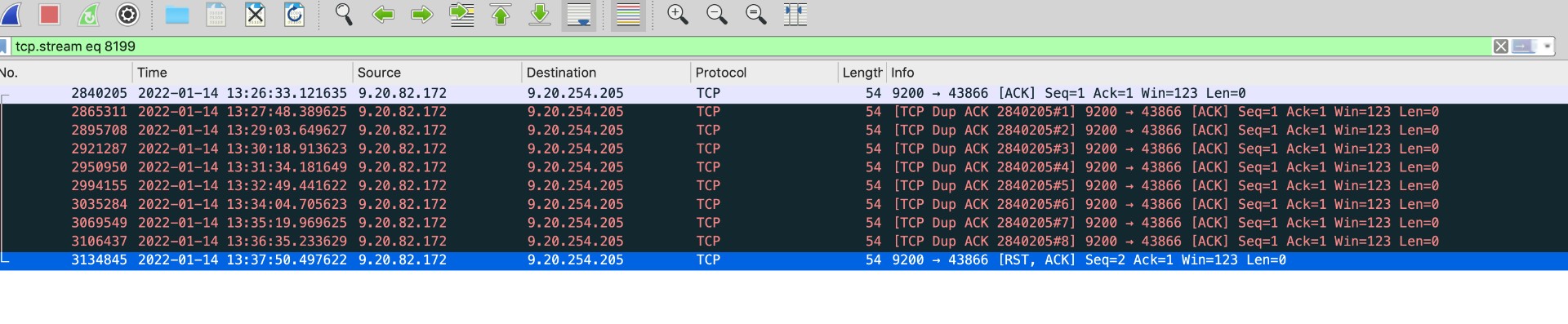
In the image above, it can be seen that at a certain moment an ES node began performing TCP keepalive checks on the gateway IP. After sending 9 keepalive packets without receiving a response, an RST packet was immediately sent back to the gateway, terminating the TCP connection. According to the network team, this kind of packet is abnormal because the client request path is client->VPC gateway->ES node. The ES node sees TCP packets from the gateway’s source IP, and as the server, it should not be actively keepalive checking the gateway. Upon checking the TCP keepalive configuration of the ES cluster node (CentOS 7), the default options were found to be:
net.ipv4.tcp_keepalive_intvl = 75net.ipv4.tcp_keepalive_probes = 9net.ipv4.tcp_keepalive_time = 7200This means a TCP connection that hasn’t had traffic for over 2 hours would have the system actively sending keepalive packets. However, these requests were sent directly to the gateway, which would not respond, leading to the RST packet after 9 attempts and thereby closing the TCP connection.
The client’s business was continuously running, so why would a connection have no traffic for over 2 hours? Through reviewing the ES High Level Rest Client code, it was found that the client uses a client connection pool with 30 instances by default. Each client holds one HTTP connection, and the keep-alive strategy is employed to reuse connections. However, this client does not keep connections alive actively, meaning that a connection could potentially remain inactive for 2 hours in the pool. Furthermore, the client will not actively remove truly unusable connections from the pool, such as those severed by the server, leading to connection reset by peer errors if using such a connection.
As for the direct request timeout error, our network colleagues explained that the VPC gateway comes with a default policy for clearing expired sessions. If a TCP connection exceeds two hours without traffic, the gateway will clear it because the gateway itself is a distributed cluster with limited load and memory capacity, preventing unlimited connection maintenance.
Now that the cause of the issue is clear, how should it be resolved? The client should actively enable TCP keepalive to prevent connections in the pool from remaining inactive for over 2 hours, allowing the server to avoid explicit keepalive checks with the gateway. Research in the ES open-source community also discusses similar issues: occasional occurrence of SocketTimeoutException or connection reset by peer when accessing a cluster via a gateway or load balancer (https://github.com/elastic/elasticsearch/issues/59261). The community’s developers decided to enable the TCP keepalive strategy by default for the ES High Level Rest client to resolve such issues (https://github.com/elastic/elasticsearch/issues/65213). Until this feature is implemented, the temporary solutions are:
- First, explicitly enable the TCP keepalive option in the client code: setSoKeepAlive(true)
final RestClientBuilder restClientBuilder = RestClient.builder(/* fill in arguments here */); // optionally perform some other configuration of restClientBuilder here if needed restClientBuilder.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder /* optionally perform some other configuration of httpClientBuilder here if needed */ .setDefaultIOReactorConfig(IOReactorConfig.custom() /* optionally perform some other configuration of IOReactorConfig here if needed */ .setSoKeepAlive(true) .build())); final RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);- Second, set the system-level TCP keepalive detection interval to 300 seconds, sending a keepalive packet every 5 minutes. The default 7200 seconds is too long and may cause the gateway to actively sever the connection.
Using the above temporary solution, the client conducted a gray release test, and client timeouts or connection reset by peer errors no longer occurred.
It is worth noting that some in the open-source community have asked whether it is possible to set setKeepAliveStrategy explicitly in the client and then shorten the keep-alive time, for example, to 3 minutes:
RestClientBuilder builder = RestClient.builder(httpHosts.toArray(new HttpHost[0])); builder.setRequestConfigCallback( new RestClientBuilder.RequestConfigCallback() { @Override public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder) { return requestConfigBuilder.setConnectTimeout(elasticsearchProperties.getConnectTimeout()) .setSocketTimeout(elasticsearchProperties.getSocketTimeout()); } }); // builder.setHttpClientConfigCallback(requestConfig -> requestConfig.setKeepAliveStrategy( (response, context) -> TimeUnit.MINUTES.toMillis(3))); RestHighLevelClient client = new RestHighLevelClient(builder);In fact, this method is unrelated to TCP keepalive. It refers to the maximum time an HTTP connection can be reused in the connection pool. If it exceeds this time, the connection will no longer be reused and will be closed by the server, subsequently establishing a new HTTP connection. This approach does address the issue of the gateway breaking the connection; however, due to frequent connection creation and closure, it is less efficient and can degrade client performance, so it is not recommended.