

Basic Environment
Here is the rewritten content with the inclusion of the keyword “nginx configuration”:”Version Information: Include instructions related to the nginx configuration to ensure the server is properly set up.”
- Centos 7.1
- nginx version: openresty/1.13.6.2
nginx Configuration Information
Code language: javascriptCopy
stream { server { listen 53 udp; proxy_pass close_stream_backend; } upstream close_stream_backend { server 10.0.1.2:53; server 10.0.1.3:53; }}Exception Issue
After stress testing with 20 threads for one minute, the two target machines alternately started crashing (no issue with single-thread access), with logs as shown below:
Code language: javascriptCopy
[error] 7184#0: *142585778 no live upstreams while connecting to upstream, udp client: 10.0.1.2, server: 0.0.0.0:53, upstream: "dns", bytes from/to client:40/0, bytes from/to upstream:0/0There are mainly two points of confusion: Firstly, directly accessing the target machines shows they are in a normal access state and not under pressure; secondly, if the load-balancing target service machines are reduced to one, this exception doesn’t occur, but the service machine’s load becomes very high. Thus, I suspect an issue with the nginx machine.
Analysis and Resolution
- On checking the nginx official website for load balancing strategies, the basic idea is as follows: The default nginx configuration is round-robin. Load balancing modules form a linked list, processed from the start each time. If a connection fails, it tries the next. If all fail, quick recovery is triggered, resetting each peer’s fail count to 0, returning NGX_BUSY, and nginx prints a no live upstreams error. Reviewing the configuration file, if one server fails once, nginx marks it as down and directs all future traffic to the other server. If the other server fails once too, both are marked down, and the error log starts printing.
- The first solution considered was to increase the retry count and time, changing
max_fails=5 fail_timeout=60sfrom 1 to 5. This reduced the no live upstreams occurrence significantly but did not eliminate it. Also, the QPS during stress testing didn’t reach desired levels, worse than a single machine. - Using
tcpdump -i eth2 udp port 53 -s0 -XXnnand analyzing with wireshark showed that data from the pressure testing tool was fully sent to the nginx machine, but the machine was not processing it correctly. - Considering nginx’s use of the epoll I/O multiplexing model, which is based on the Linux kernel, the
/var/log/messageskernel logs were checked, revealing many packet drop logs:
Code language: javascriptCopy
kernel: nf_conntrack: table full, dropping packet.To verify the issue, pressure data was resent, only to find these kernel packet drop logs appearing again under stress testing. It’s suspected that high access volume with inappropriate kernel netfilter module conntrack configuration ultimately led to new connections being dropped.
- Checking netfilter parameter configuration with
sudo sysctl -a | grep conntrackshowed 65536, and it was directly increased fourfold.
Code language: javascriptCopy
sudo sysctl -w net.netfilter.nf_conntrack_max=262144sudo sysctl -w net.nf_conntrack_max=262144Executing sudo sysctl -p applied the settings immediately. Stress testing again revealed no packet drops in the kernel, and nginx did not log the previous errors. The issue was resolved.
Summary Analysis
This article primarily analyzes nginx network request anomalies, identifying undersized kernel parameter settings as the cause of packet drops, solved by modifying kernel configurations. But what is conntrack? After researching, conntrack targets stateful firewalls. For more, read about Netfilter’s connection tracking system, including Netfilter’s basic framework. Thus, conntrack is used to log connection states for traffic inspection and to mitigate DDoS security issues.
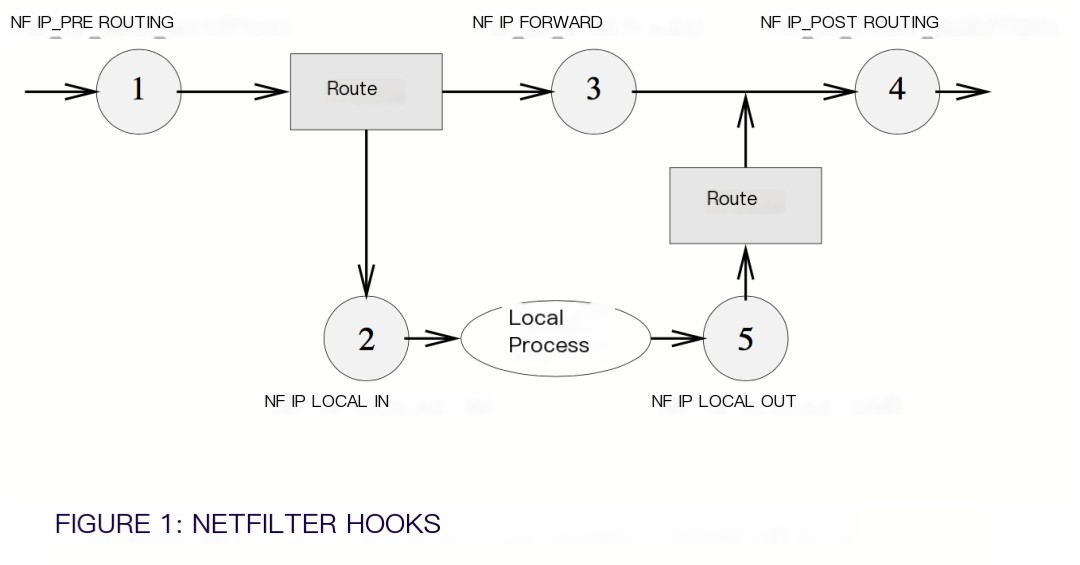 >
>
During problem analysis, I directly set conntrack to four times its previous value. Is this reasonable? How should one configure such settings when faced with similar issues? Below is a formula: Recommended size: CONNTRACK_MAX = RAMSIZE (in bytes) / 16384 / (ARCH / 32). For example, on an x86_64 OS with 8GB RAM, it’s set to 8*1024^3/16384/2=262144. This summarizes my process to solve the issue. For questions, follow the public account, add me on WeChat, and let’s discuss!